Approximating Latent Manifolds in Neural Networks via Vanishing Ideals
Our ICML25 paper Approximating Latent Manifolds in Neural Networks via Vanishing Ideals introduces a novel approach to understanding data representation in neural networks through vanishing ideals. To characterize the structure of latent spaces, we scale vanishing ideal algorithms to handle high-dimensional data. The resulting algebraic characterizations can be used to replace standard network layers with more compact and efficient polynomial layers, leading to significant parameter reduction and potential improvements in inference speed while maintaining competitive performance.
The Manifold Hypothesis
A foundational concept in understanding the efficacy of deep neural networks is the Manifold Hypothesis
Neural networks are often conceptualized as learning complex functions that progressively transform these input data manifolds. Through successive layers, a network can reshape and disentangle these manifolds, ideally leading to representations in its latent spaces where the data becomes more structured or even linearly separable for tasks like classification
To characterize these latent manifolds, we seek to find their algebraic descriptions. Fortunately, many manifolds encountered in such settings can be described as the zero set of a system of polynomial equations. Such a system formally defines an algebraic variety. For example, a sphere in three-dimensional Euclidean space, representing a simple manifold, is defined by all points $(x, y, z)$ that satisfy the single polynomial equation $x^2 + y^2 + z^2 - r^2 = 0$. This algebraic perspective is central to our work, which pursues two primary objectives. First, we investigate whether these complex latent manifolds can be accurately described by a relatively small set of simple polynomial equations. The aim is to see if concise algebraic descriptions can capture the essential geometry of class-specific data representations within neural networks. Second, we explore how such polynomial characterizations, if obtainable, can be leveraged for class separation. The core idea is that even if data points from different classes are not yet linearly separable in a given latent space, their underlying manifold structures, once captured by these polynomials, might offer a direct path to distinguishing them. This is particularly interesting from an efficiency standpoint, as it suggests the possibility of replacing multiple complex, dense layers with more structured and potentially more compact polynomial computations, a concept we will explore through vanishing ideals.
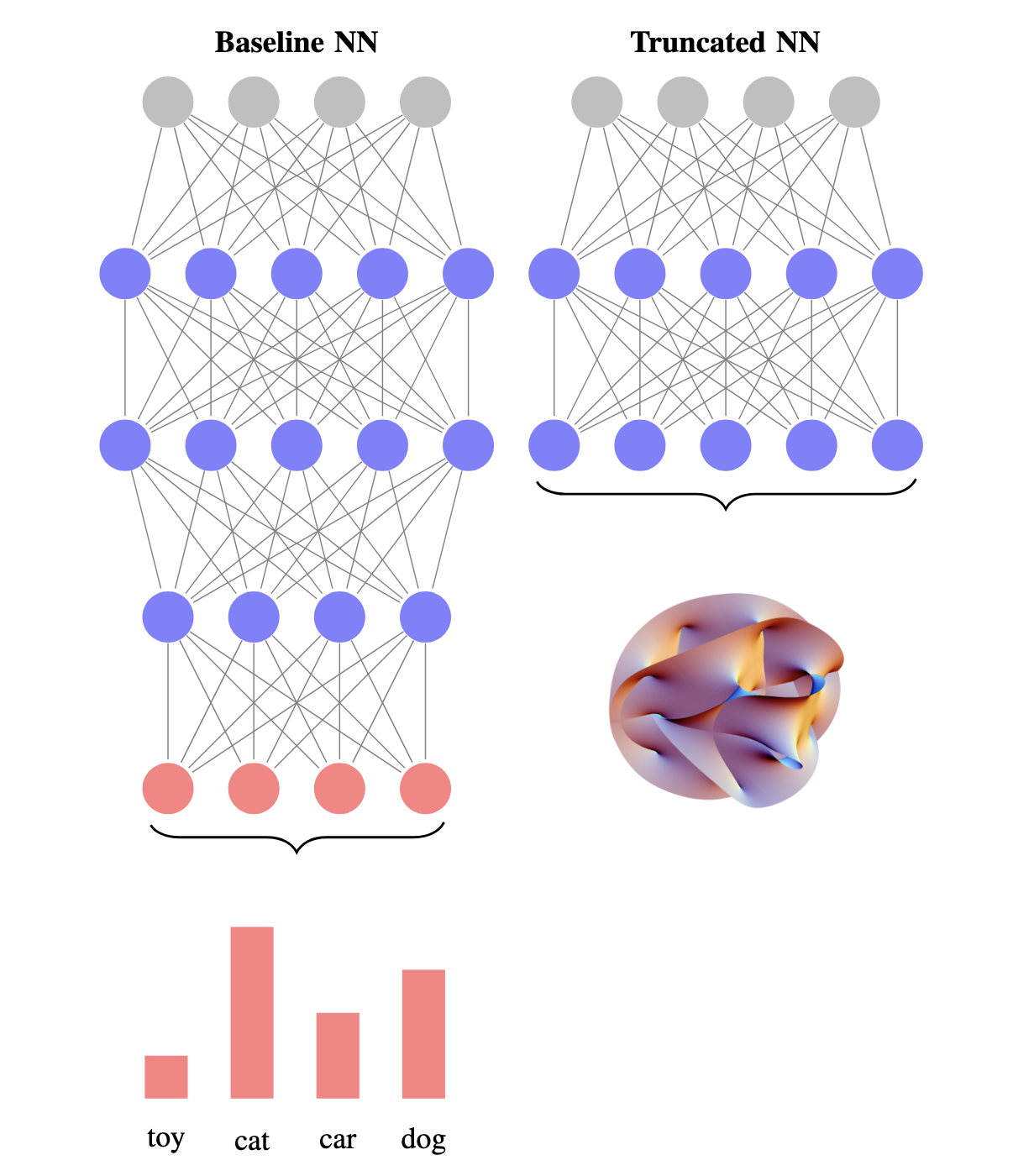
An Algebraic View on Latent Manifolds
Recall that the latent manifolds we aim to characterize can often be described as algebraic varieties—the zero set of a system of polynomial equations. When we process data through a neural network up to a certain layer, the resulting activations (our points in latent space) can be viewed as a finite set of samples $\mathbf{Z} = \{\mathbf{z}_1, \dots, \mathbf{z}_m\}$ drawn from such an underlying manifold. From this set of samples, we can seek to find its algebraic description by computing the vanishing ideal $\mathcal{I}(\mathbf{Z})$, which is the set of all polynomials $p$ such that $p(\mathbf{z}_i) = 0$ for all $\mathbf{z}_i \in \mathbf{Z}$. These polynomials approximate the algebraic structure of the variety containing $\mathbf{Z}$, noting that a sample of the manifold is of course also only an approximation to the manifold itself.
While $\mathcal{I}(\mathbf{Z})$ itself contains infinitely many polynomials, Hilbert’s Basis Theorem guarantees that it can be finitely generated. This means there exists a finite set of polynomials, known as generators, from which all other polynomials in the ideal can be derived through polynomial combinations and multiplications. The primary goal of vanishing ideal algorithms is to find such a set of generators, thereby providing a concise algebraic description of the data’s underlying structure.
However, in practice, data from neural network latent spaces is often noisy, and we only have a finite number of samples. Attempting to find polynomials that vanish perfectly on these samples is typically impossible. Moreover, even if such polynomials were found, they would describe the specific sample set $\mathbf{Z}$ rather than generalizing to the underlying manifold $U$ from which $\mathbf{Z}$ was drawn. Therefore, instead of exact vanishing, we seek polynomials that approximately vanish on the data. That is, we look for polynomials $p$ such that $p(\mathbf{z}_i)^2 \leq \psi$ for all $\mathbf{z}_i \in \mathbf{Z}$, where $\psi > 0$ is a small tolerance. Algorithms such as the Oracle Approximate Vanishing Ideal (OAVI) algorithm
Our first main goal is to characterize the structure of class-specific data manifolds as they are represented in the latent spaces of pre-trained neural networks. This involves applying vanishing ideal algorithms to the activation vectors produced by an intermediate layer of the network.
However, applying these algorithms directly to the latent space data presents significant computational challenges:
- High Dimensionality: Latent spaces, even in intermediate layers, can possess hundreds of dimensions. This poses a problem for standard vanishing ideal algorithms due to the combinatorial explosion in the number of potential monomial terms.
- Large Sample Sizes: Neural networks are typically trained on huge datasets, leading to a large number of activation vectors that need to be processed by the vanishing ideal algorithms.
- Generator Overload and Quality: Vanishing ideal algorithms can produce a huge number of generator polynomials. Many of these might be dense (involving many monomial terms) or lack the crucial property of being discriminative between different classes.
To address these challenges, we employ the following techniques:
- Stochastic Vanishing Ideal Computation: Instead of processing all data points for a class at once, we use stochastic variants of the algorithms. These operate on random subsets (mini-batches) of the latent activations, significantly reducing computational load and memory requirements.
- Dimensionality Reduction: Before applying vanishing ideal algorithms, we use PCA on the latent activations.
- Data Preprocessing for Numerical Stability: To improve the numerical stability of polynomial computations, latent activations are rescaled (e.g., via a Tanh transformation to map them into the $[-1,1]^n$ hypercube). We also explore using reduced arithmetic precision, which can further alleviate computational demands.
- Selection of Discriminative and Sparse Generators through Pruning: Despite the aforementioned optimizations, the initial set of computed generators can still be very large, resulting in a large number of polynomials to evaluate during inference. We address this by removing (or pruning) polynomials that are not discriminative of the class. For each class, we evaluate its candidate polynomials. A polynomial is deemed valuable if it is discriminative—meaning it effectively vanishes (evaluates to near zero) on samples of its own class while remaining significantly non-zero on samples from other classes. Polynomials that don’t sufficiently meet this criterion are discarded. Alongside discriminative power, we prioritize sparsity: we favor polynomials with fewer monomial terms, as these are computationally more efficient to evaluate. Algorithms like ABM
and OAVI (especially when OAVI is used with the Frank-Wolfe algorithm) are good at producing such sparse polynomials. This dual-pruning strategy is essential: it not only selects for the most discriminative polynomials but also significantly reduces their total number and the complexity of their evaluation, leading to a compact and effective algebraic characterization of each class manifold.
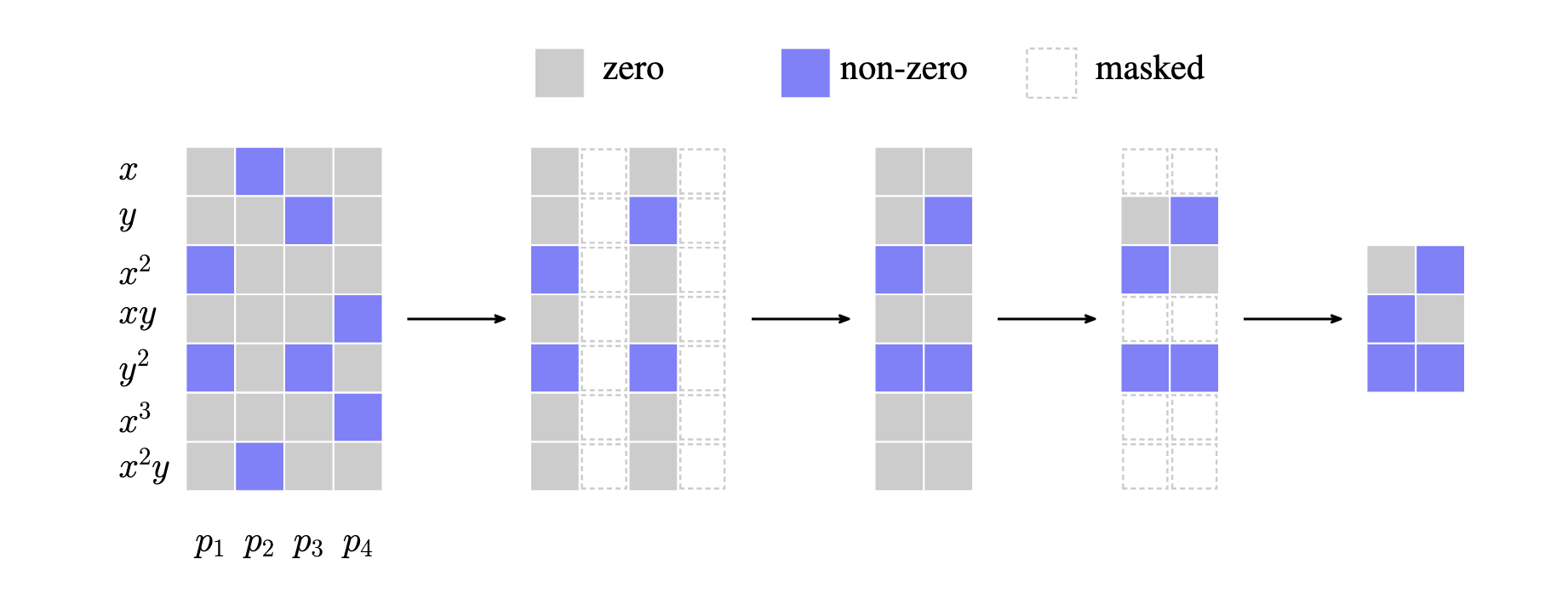
VI-Net: Replacing Network Layers with Polynomial Expansions
Now that we have established methods for approximating the class-specific manifolds in a neural network’s latent space via their (approximate) vanishing ideal generators, we can make use of this algebraic insight. A primary goal is to enhance the efficiency of pre-trained neural networks. Deep networks, while powerful, often contain many computationally expensive layers. We propose replacing a significant portion of these final layers with a single, more structured polynomial layer built from the pruned generators discussed earlier.
The fundamental concept is based on how these polynomial generators can achieve class separation. Even if data classes are not linearly separable in the chosen latent space of the truncated network, their distinct manifold structures, captured by the polynomial generators $\{p_i^k\}_{i=1}^{n_k}$ for each class $k$, can lead to polynomial separability. We achieve this by constructing a transformation $G$ as follows. For any latent vector $\mathbf{z}$ (the output of the truncated network), this transformation is defined as:
\[G(\mathbf{z}) = (|p_1^1(\mathbf{z})|, \dots, |p_{n_1}^1(\mathbf{z})|, \dots, |p_1^K(\mathbf{z})|, \dots, |p_{n_K}^K(\mathbf{z})|)\]Here, $p_i^k$ is the $i$-th generator for class $k$, $K$ is the total number of classes, and $n_k$ is the number of generators for class $k$. The crucial property of this transformation is that if the input latent vector $\mathbf{z}$ belongs to a particular class $j$, its own generators $p_i^j(\mathbf{z})$ will evaluate to values very close to zero (as they approximately vanish on class $j$’s manifold). Conversely, the generators $p_i^l(\mathbf{z})$ for other classes $l \neq j$ will likely evaluate to significantly non-zero values. The output vector $G(\mathbf{z})$ thus has near-zero entries for the block of features corresponding to the true class $j$ and larger values for other blocks. This structure makes the transformed features linearly separable by a simple linear classifier. Our architecture that implements this approach is named VI-Net, and it represents our second main contribution.
The VI-Net training pipeline is as follows:
- Truncate Network: Start with a pre-trained neural network $\phi$ and truncate it at an intermediate layer $L’$.
- Compute Vanishing Ideals: For each class $k$, extract the latent activations $\mathbf{Z}^k = \phi_{L’}(\mathbf{X}^k)$ and compute a set of approximate vanishing ideal generators using the adapted algorithms described above. Here, $\mathbf{X}^k$ is the set of samples from class $k$.
- Prune Generators: Apply the pruning strategy to select the most discriminative and sparse polynomials for each class.
- Construct Polynomial Layer: Use the selected and pruned generators $\{p_i^k\}_{i=1}^{n_k}$ for all classes to implement the transformation $G(\mathbf{z})$ as defined above.
- Fine-tune: Append a simple linear classifier to the polynomial layer. Then, fine-tune the coefficients of the polynomials within the polynomial layer and the weights of the linear classifier using standard gradient descent.
This approach offers several potential benefits, primarily from an efficiency perspective:
- Parameter Reduction: The polynomial layer, especially after pruning, can have significantly fewer parameters than the multiple convolutional or fully connected layers it replaces. This leads to smaller model sizes.
- Computational Speed-up: Evaluating a typically sparse polynomial layer can be faster than executing several dense layers, potentially increasing inference throughput.
Our experiments demonstrate these benefits. For example, VI-Net variants built on ResNet architectures for CIFAR-10 and CIFAR-100 achieve classification accuracy comparable to the original, larger baseline networks, even when a substantial number of layers are replaced.
VI-Nets can be significantly more parameter-efficient and exhibit higher throughput, as shown in the table below.
| CIFAR-10 (ResNet-18) | |||||
|---|---|---|---|---|---|
| Model | Total Params | Base Params | Poly Params | Acc (%) | Throughput (img/s) |
| VI-Net18-Tiny | 1.86M | 0.68M | 1.18M | 88.62 | 100798 ± 20506 |
| VI-Net18-Small | 2.84M | 2.18M | 0.66M | 92.66 | 79307 ± 15576 |
| VI-Net18-Medium | 4.35M | 3.96M | 0.39M | 92.92 | 71851 ± 13987 |
| VI-Net18-Large | 9.20M | 8.81M | 0.39M | 93.02 | 62086 ± 11291 |
| ResNet18 | 11.24M | 11.24M | - | 92.89 | 66533 ± 12577 |
Conclusion and Outlook
This research creates a practical connection between manifold learning in neural networks and computational algebra. By adapting vanishing ideal algorithms, we effectively characterize the algebraic structure of class-specific manifolds within deep network latent spaces. The proposed VI-Net architecture demonstrates that these algebraic characterizations can construct polynomial layers to replace standard network components. This in turn yields models that are more parameter-efficient and can achieve faster inference while maintaining competitive accuracy.
If you find this work useful, please consider citing our paper:
@inproceedings{pelleriti2025approximatinglatentmanifoldsneural,
title = {Approximating Latent Manifolds in Neural Networks via Vanishing Ideals},
author = {Pelleriti, Nico and Zimmer, Max and Wirth, Elias and Pokutta, Sebastian},
booktitle = {Forty-second International Conference on Machine Learning},
year = {2025},
url = {https://openreview.net/forum?id=WYlerYGDPL},
}