Publications tagged "model-internals"
-
 ICML26 Forty-third International Conference on Machine Learning 2026
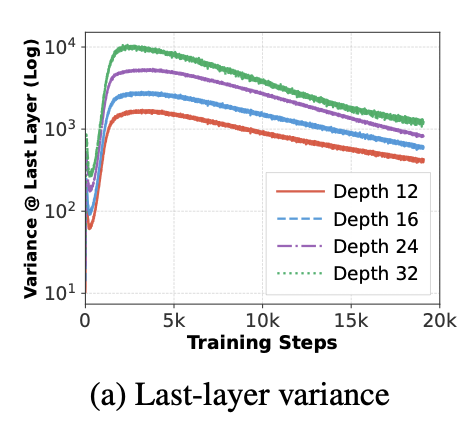
ICML26 Forty-third International Conference on Machine Learning 2026Recent work has demonstrated the curse of depth in large language models (LLMs), where later layers contribute less to learning and representation than earlier layers. Such under-utilization is linked to the accumulated growth of variance in Pre-Layer Normalization, which can push deep blocks toward near-identity behavior. In this paper, we demonstrate that, sparsity, beyond enabling efficiency, acts as a regulator of variance propagation and thereby improves depth utilization. Our investigation covers two sources of sparsity: (i) implicit sparsity, which emerges from training and data conditions, including weight sparsity induced by weight decay and attention sparsity induced by long-context inputs; and (ii) explicit sparsity, which is enforced by architectural design, including key/value-sharing sparsity in Grouped-Query Attention and expert-activation sparsity in Mixture-of-Experts. Our claim is thoroughly supported by controlled depth-scaling experiments and targeted layer effectiveness interventions. Across settings, we observe a consistent relationship: sparsity improves layer utilization by reducing output variance and promoting functional differentiation. We eventually distill our findings into a practical rule-of-thumb recipe for training depth-effective LLMs, yielding a notable 4.6% accuracy improvement on downstream tasks. Our results reveal sparsity, arising naturally from standard design choices, as a key yet previously overlooked mechanism for effective depth scaling in LLMs.
@inproceedings{muhtar2026when, title = {When Does Sparsity Mitigate the Curse of Depth in {LLM}s}, author = {Muhtar, Dilxat and Song, Xinyuan and Pokutta, Sebastian and Zimmer, Max and Pelleriti, Nico and Hofmann, Thomas and Liu, Shiwei}, booktitle = {Forty-third International Conference on Machine Learning}, year = {2026}, } -
 ICML26 Forty-third International Conference on Machine Learning 2026
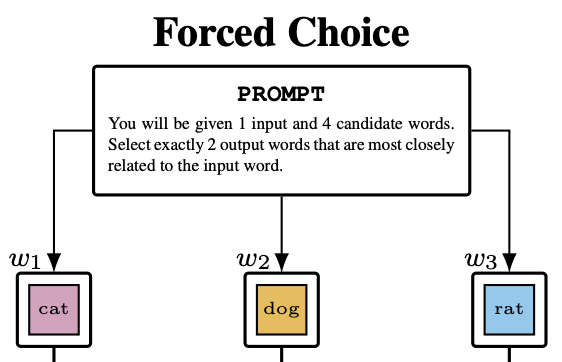
ICML26 Forty-third International Conference on Machine Learning 2026We investigate the extent to which an LLM’s hidden-state geometry can be recovered from its behavior in psycholinguistic experiments. Across eight instruction-tuned transformer models, we run two experimental paradigms – similarity-based forced choice and free association – over a shared 5,000-word vocabulary, collecting 17.5M+ trials to build behavior-based similarity matrices. Using representational similarity analysis, we compare behavioral geometries to layerwise hidden-state similarity and benchmark against FastText, BERT, and cross-model consensus. We find that forced-choice behavior aligns substantially more with hidden-state geometry than free association. In a held-out-words regression, behavioral similarity (especially forced choice) predicts unseen hidden-state similarities beyond lexical baselines and cross-model consensus, indicating that behavior-only measurements retain recoverable information about internal semantic geometry. Finally, we discuss implications for the ability of behavioral tasks to uncover hidden cognitive states.
@inproceedings{schiekiera2026associations, title = {From Associations to Activations: Comparing Behavioral and Hidden-State Semantic Geometry in LLMs}, author = {Schiekiera, Louis and Zimmer, Max and Roux, Christophe and Pokutta, Sebastian and G{\"u}nther, Fritz}, booktitle = {Forty-third International Conference on Machine Learning}, year = {2026}, } -
We propose an interactive multi-agent classifier that provides provable interpretability guarantees even for complex agents such as neural networks. These guarantees consist of lower bounds on the mutual information between selected features and the classification decision. Our results are inspired by the Merlin-Arthur protocol from Interactive Proof Systems and express these bounds in terms of measurable metrics such as soundness and completeness. Compared to existing interactive setups, we rely neither on optimal agents nor on the assumption that features are distributed independently. Instead, we use the relative strength of the agents as well as the new concept of Asymmetric Feature Correlation which captures the precise kind of correlations that make interpretability guarantees difficult. We evaluate our results on two small-scale datasets where high mutual information can be verified explicitly.
@inproceedings{waldchen2024interpretability, title = {Interpretability Guarantees with Merlin-Arthur Classifiers}, author = {W{\"a}ldchen, Stephan and Sharma, Kartikey and Turan, Berkant and Zimmer, Max and Pokutta, Sebastian}, booktitle = {International Conference on Artificial Intelligence and Statistics}, year = {2024}, }