Publications tagged "optimization"
-
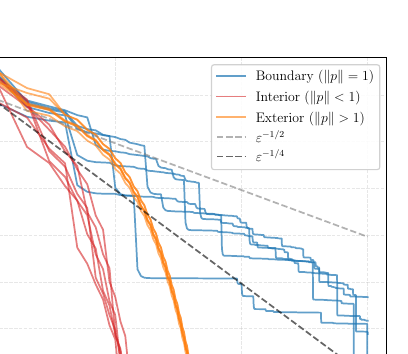 J. Halbey, D. Deza, M. Zimmer, C. Roux, B. Stellato, and 1 more authorICML26 Forty-third International Conference on Machine Learning 2026
J. Halbey, D. Deza, M. Zimmer, C. Roux, B. Stellato, and 1 more authorICML26 Forty-third International Conference on Machine Learning 2026We present a constructive lower bound demonstrating that Frank-Wolfe optimization requires Ω(1/√ε) iterations when both the objective function and constraint set possess smoothness and strong convexity. This result confirms that existing convergence guarantees of O(1/√ε) are optimal. We focus on a representative problem: minimizing a strongly convex quadratic over a Euclidean unit ball with the optimizer positioned at the boundary. We introduce a novel computational method for constructing worst-case trajectories and provide an analytical proof establishing our theoretical bound.
@inproceedings{halbey2026lower, title = {Lower Bounds for Frank-Wolfe on Strongly Convex Sets}, author = {Halbey, Jannis and Deza, Daniel and Zimmer, Max and Roux, Christophe and Stellato, Bartolomeo and Pokutta, Sebastian}, booktitle = {Forty-third International Conference on Machine Learning}, year = {2026}, } -
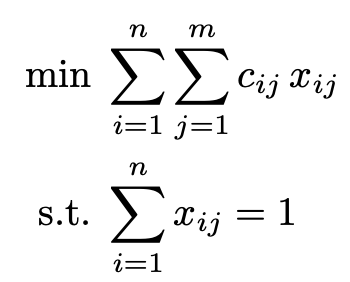 D. Kuzinowicz, P. Lichocki, G. Mexi, M. E. Pfetsch, S. Pokutta, and 1 more authorPreprintarXiv preprint arXiv:2512.10507 2025
D. Kuzinowicz, P. Lichocki, G. Mexi, M. E. Pfetsch, S. Pokutta, and 1 more authorPreprintarXiv preprint arXiv:2512.10507 2025This article investigates the interplay of rounding objective coefficients in binary programs and almost symmetries. Empirically, reducing the number of significant bits through rounding often leads to instances that are easier to solve. One reason can be that the amount of symmetries increases, which enables solvers to be more effective when they are exploited. This can signify that the original instance contains ’almost symmetries’. Furthermore, solving the rounded problems provides approximations to the original objective values. We empirically investigate these relations on instances of the capacitated facility location problem, the knapsack problem and a diverse collection of additional instances, using the solvers SCIP and CP-SAT. For all investigated problem classes, we show empirically that this yields faster algorithms with guaranteed solution quality. The influence of symmetry depends on the instance type and solver.
@article{kuzinowicz2025objective, title = {Objective Coefficient Rounding and Almost Symmetries in Binary Programs}, author = {Kuzinowicz, Dominik and Lichocki, Paweł and Mexi, Gioni and Pfetsch, Marc E. and Pokutta, Sebastian and Zimmer, Max}, journal = {arXiv preprint arXiv:2512.10507}, year = {2025}, } -
 * equal contributionPreprintarXiv preprint arXiv:2510.13713 2025
* equal contributionPreprintarXiv preprint arXiv:2510.13713 2025Pruning is a common technique to reduce the compute and storage requirements of Neural Networks. While conventional approaches typically retrain the model to recover pruning-induced performance degradation, state-of-the-art Large Language Model (LLM) pruning methods operate layer-wise, minimizing the per-layer pruning error on a small calibration dataset to avoid full retraining, which is considered computationally prohibitive for LLMs. However, finding the optimal pruning mask is a hard combinatorial problem and solving it to optimality is intractable. Existing methods hence rely on greedy heuristics that ignore the weight interactions in the pruning objective. In this work, we instead consider the convex relaxation of these combinatorial constraints and solve the resulting problem using the Frank-Wolfe (FW) algorithm. Our method drastically reduces the per-layer pruning error, outperforms strong baselines on state-of-the-art GPT architectures, and remains memory-efficient. We provide theoretical justification by showing that, combined with the convergence guarantees of the FW algorithm, we obtain an approximate solution to the original combinatorial problem upon rounding the relaxed solution to integrality.
@article{roux2025dontbegreedyjustrelax, title = {Don't Be Greedy, Just Relax! Pruning LLMs via Frank-Wolfe}, author = {Roux, Christophe and Zimmer, Max and d'Aspremont, Alexandre and Pokutta, Sebastian}, journal = {arXiv preprint arXiv:2510.13713}, year = {2025}, } -
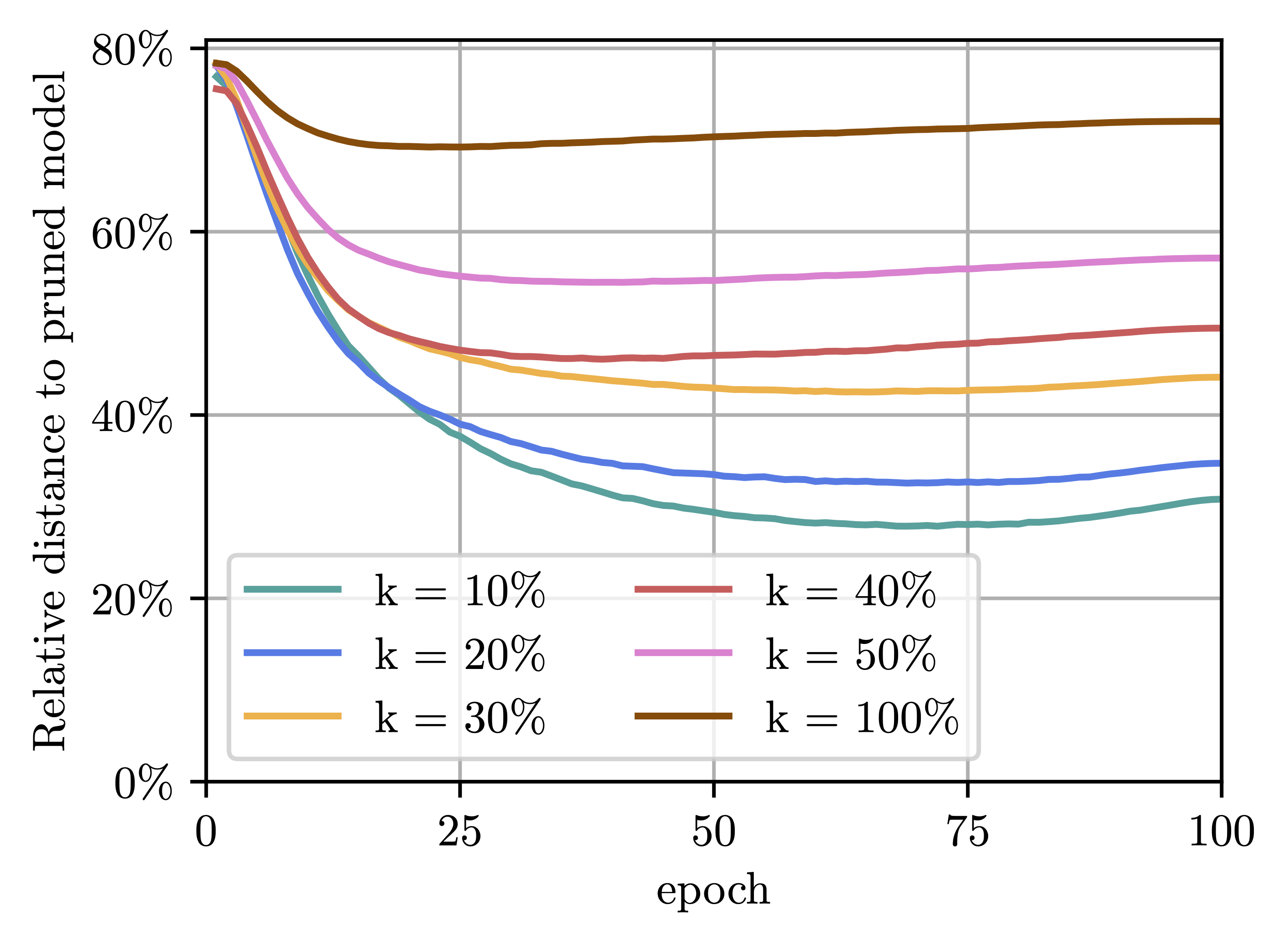 M. Zimmer, C. Spiegel, and S. PokuttaJournal Mathematical Optimization for Machine Learning 2025
M. Zimmer, C. Spiegel, and S. PokuttaJournal Mathematical Optimization for Machine Learning 2025Many existing Neural Network pruning approaches either rely on retraining to compensate for pruning-caused performance degradation or they induce strong biases to converge to a specific sparse solution throughout training. A third paradigm obtains a wide range of compression ratios from a single dense training run while also avoiding retraining. Recent work of Pokutta et al. (2020) and Miao et al. (2022) suggests that the Stochastic Frank-Wolfe (SFW) algorithm is particularly suited for training state-of-the-art models that are robust to compression. We propose leveraging k-support norm ball constraints and demonstrate significant improvements over the results of Miao et al. (2022) in the case of unstructured pruning. We also extend these ideas to the structured pruning domain and propose novel approaches to both ensure robustness to the pruning of convolutional filters as well as to low-rank tensor decompositions of convolutional layers. In the latter case, our approach performs on-par with nuclear-norm regularization baselines while requiring only half of the computational resources. Our findings also indicate that the robustness of SFW-trained models largely depends on the gradient rescaling of the learning rate and we establish a theoretical foundation for that practice.
@inbook{ZimmerSpiegelPokutta+2025+137+168, url = {https://doi.org/10.1515/9783111376776-010}, title = {Compression-aware Training of Neural Networks using Frank-Wolfe}, booktitle = {Mathematical Optimization for Machine Learning}, author = {Zimmer, Max and Spiegel, Christoph and Pokutta, Sebastian}, editor = {Fackeldey, Konstantin and Kannan, Aswin and Pokutta, Sebastian and Sharma, Kartikey and Walter, Daniel and Walther, Andrea and Weiser, Martin}, publisher = {De Gruyter}, address = {Berlin, Boston}, pages = {137--168}, doi = {doi:10.1515/9783111376776-010}, isbn = {9783111376776}, year = {2025}, } -
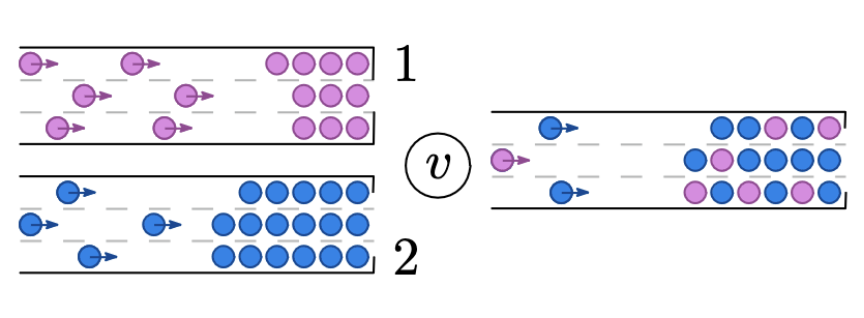 T. Ziemke, L. Sering, L. V. Koch, M. Zimmer, K. Nagel, and 1 more authorJournalTransportation Research Procedia 2021
T. Ziemke, L. Sering, L. V. Koch, M. Zimmer, K. Nagel, and 1 more authorJournalTransportation Research Procedia 2021This study examines the connection between an agent-based transport simulation and Nash flows over time. While the former is able to represent many details of traffic and model large-scale, real-world traffic situations with a co-evolutionary approach, the latter provides an environment for provable mathematical statements and results on exact user equilibria. The flow dynamics of both models are very similar with the main difference that the simulation is discrete in terms of vehicles and time while the flows over time model considers continuous flows and continuous time. This raises the question whether Nash flows over time are the limit of the convergence process when decreasing the vehicle and time step size in the simulation coherently. The experiments presented in this study indicate this strong connection which provides a justification for the analytical model and a theoretical foundation for the simulation.
@article{ziemke2021flows, title = {Flows over time as continuous limits of packet-based network simulations}, author = {Ziemke, Theresa and Sering, Leon and Koch, Laura Vargas and Zimmer, Max and Nagel, Kai and Skutella, Martin}, journal = {Transportation Research Procedia}, volume = {52}, pages = {123--130}, year = {2021}, publisher = {Elsevier}, } -
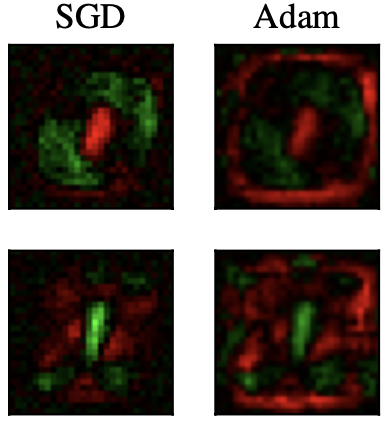 S. Pokutta, C. Spiegel, and M. ZimmerPreprintarXiv preprint arXiv:2010.07243 2020
S. Pokutta, C. Spiegel, and M. ZimmerPreprintarXiv preprint arXiv:2010.07243 2020This paper studies the empirical efficacy and benefits of using projection-free first-order methods in the form of Conditional Gradients, a.k.a. Frank-Wolfe methods, for training Neural Networks with constrained parameters. We draw comparisons both to current state-of-the-art stochastic Gradient Descent methods as well as across different variants of stochastic Conditional Gradients. In particular, we show the general feasibility of training Neural Networks whose parameters are constrained by a convex feasible region using Frank-Wolfe algorithms and compare different stochastic variants. We then show that, by choosing an appropriate region, one can achieve performance exceeding that of unconstrained stochastic Gradient Descent and matching state-of-the-art results relying on L^2-regularization. Lastly, we also demonstrate that, besides impacting performance, the particular choice of constraints can have a drastic impact on the learned representations.
@article{pokutta2020deep, title = {Deep Neural Network training with Frank-Wolfe}, author = {Pokutta, Sebastian and Spiegel, Christoph and Zimmer, Max}, journal = {arXiv preprint arXiv:2010.07243}, year = {2020}, }