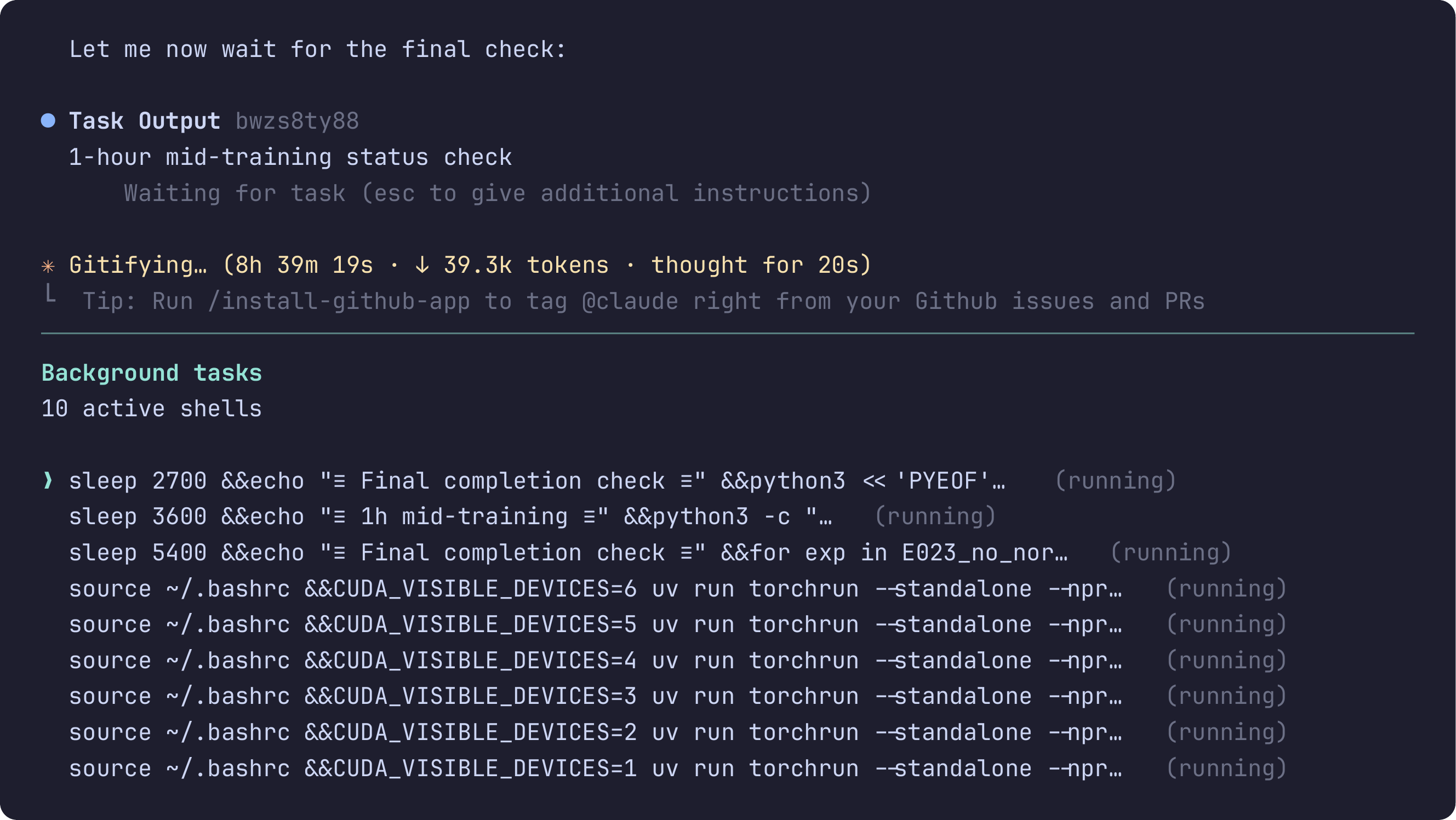
An autonomous research session running for over 8 hours, dispatching independent experiments across 6 GPUs with 10 active background tasks.
The Framework
The Agentic Researcher is an open-source framework that turns CLI coding agents into autonomous research assistants. The core idea: encode scientific methodology as agent prompts, so that the agent follows the same principles a careful researcher would.
In practice, the researcher provides a research question, available tools, and relevant prior knowledge. The agent then takes over: it formalizes ideas, implements approaches, runs evaluations, analyzes results, and maintains a structured LaTeX report. Sessions can run for hours or days without human intervention, with the researcher checking in and steering as needed.
Sandboxed
Runs in isolated containers (Docker, Podman, Apptainer) with filesystem access restricted to /workspace.
Model-Agnostic
Works with any CLI coding agent: Claude Code, OpenCode, Gemini CLI, or Codex CLI.
Scalable
From single-GPU laptops to multi-node Slurm clusters with GPU passthrough.
Getting Started
The full source code and documentation are available at github.com/ZIB-IOL/The-Agentic-Researcher.
Installation
git clone https://github.com/ZIB-IOL/The-Agentic-Researcher.git
cd The-Agentic-Researcher
./scripts/install.sh
Configuration
Run agentic-researcher --setup to configure your environment. This stores settings in ~/.config/agentic-researcher/config.sh and covers:
- Container runtime: Docker, Podman, or Apptainer (Linux)
- CLI tool: Claude Code (default), OpenCode, Gemini CLI, or Codex CLI
- Authentication: OAuth or API key for the chosen tool
- Bind directories: Additional filesystem paths to mount into the container
- Environment variables: Proxy settings, custom endpoints
Starting a Session
# Build the container (first time only)
agentic-researcher --build
# Launch on the current directory
agentic-researcher
# Or target a specific project
agentic-researcher ~/my-project
# Auto-approve all agent operations
agentic-researcher --yolo
Inside the container, run /setup_research_plan to initialize a new project. The agent will ask about your research goals, evaluation metrics, compute budget, and constraints. It then creates the instruction file (CLAUDE.md, GEMINI.md, or AGENTS.md depending on your tool), initializes report.tex and TODO.md, and begins autonomous execution.
Resuming a Session
Relaunching on an existing project automatically restores context. The agent reads report.tex, TODO.md, and the git log to pick up where it left off.
Multi-Node Dispatch
For cluster environments with Slurm:
# Requires Apptainer and an active allocation
agentic-researcher --multi-node
# Validate the setup first
agentic-researcher --multi-node --test
The agent uses git worktrees for parallel sessions, so independent experiments run on separate copies of the codebase without interfering with each other.
The Experiment Loop
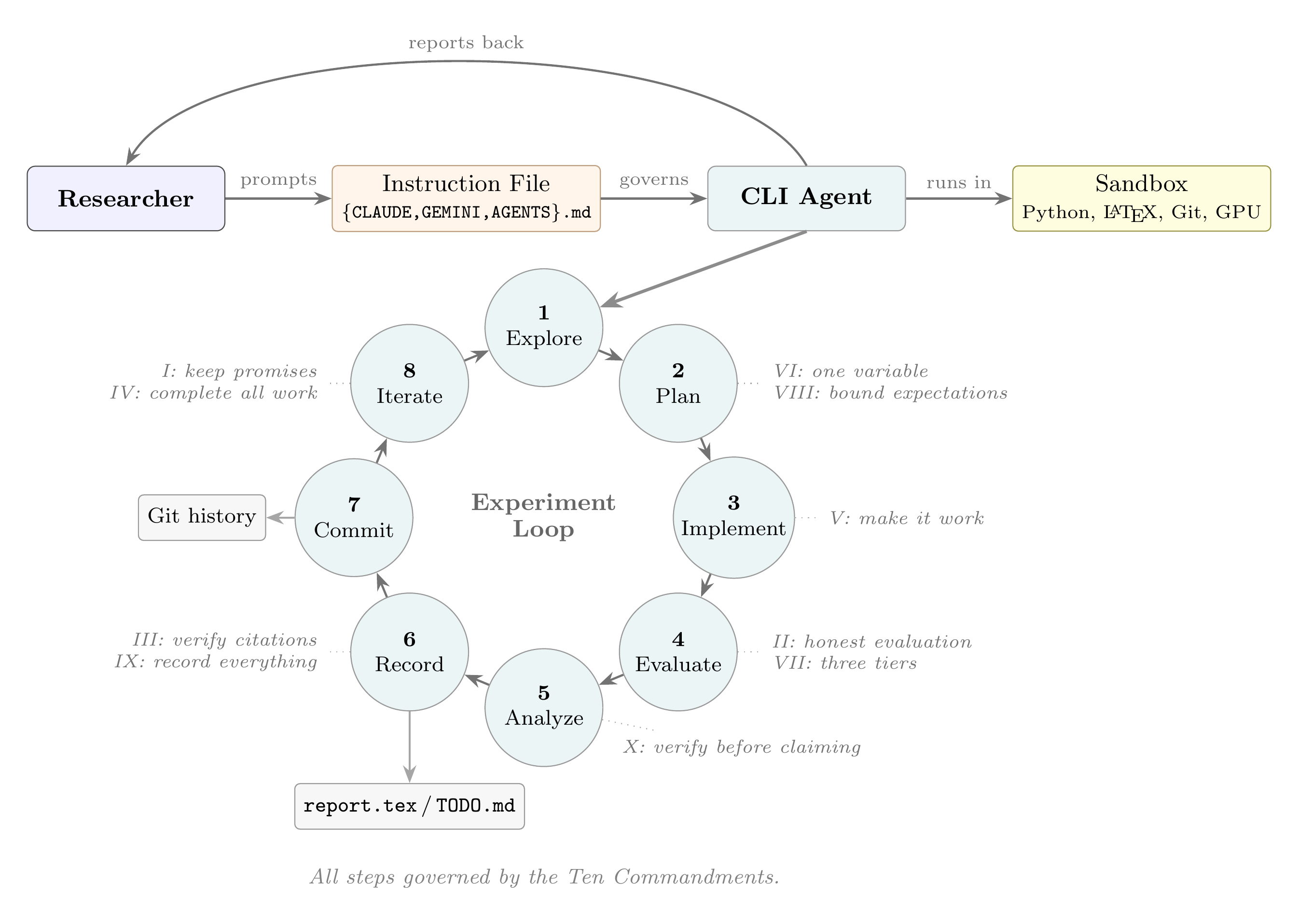
Overview of the framework. The researcher writes a persistent instruction file that governs the CLI agent. The agent runs inside a sandbox and follows an eight-step experiment loop, with each step linked to the commandments that govern it.
Once initialized, the agent follows an eight-step loop for each experiment:
- Explore the current state of the project and prior results
- Plan the next experiment based on the research plan and findings so far
- Implement the approach, making minimal, targeted changes
- Evaluate in tiers: crash test (seconds), small-scale signal (minutes), then full evaluation
- Analyze results against the hypothesis and prior experiments
- Record everything in
report.texwith a fixed structure: goal, hypothesis, method, implementation, results, analysis, next steps - Commit with structured messages:
exp(E001): description -- metric=value - Iterate back to step 1
Negative results are documented with the same rigor as positive ones. Every experiment is committed to git, making the full history reproducible and auditable.
The Ten Commandments
What makes autonomous sessions productive is not the underlying LLM but the methodological rules governing it. Without these rules, agents drift from the plan, fabricate results, or abandon promising directions after minor setbacks. We encode these rules as prompts that the agent follows throughout the session.
Integrity
I. Never Break a Promise
If you say "I will do X," do it. Under-promise, over-deliver.
II. Never Manipulate Evaluation
No changing metrics, test sets, or fixed parameters. No hardcoding results or cherry-picking seeds.
III. Never Fabricate Citations
Every bibliography entry must be verified against the actual source.
Scientific Rigor
VI. One Variable Per Experiment
Change exactly one thing. If two things change and the metric improves, you cannot know which helped.
VII. Evaluate in Tiers
Tier 1 (seconds): does it run? Tier 2 (minutes): any signal? Tier 3: full evaluation for the report.
VIII. Bound Your Expectations
Identify the theoretical best case before implementing. Know whether a 2% gain is nearly optimal or barely scratching the surface.
Autonomy and Documentation
IV. Complete All Work Before Reporting
Finish every task that does not need user input. Report once with all results.
V. Make It Work Before Moving On
An experiment crash is a bug, not a bad idea. Investigate, fix, and re-run.
IX. Record Everything
Every experiment gets a subsection in report.tex. Include failures. If it is not in the report, it did not happen.
X. Verify Before Claiming
Write verification scripts, not explanations. Actively try to falsify claims.
Beyond these universal rules, the framework includes domain-specific commandments for compute-intensive research (one experiment per GPU, context window hygiene, systematic memory management, multi-node discovery) and mathematical research (derivations before code, precise notation, counterexample-first reasoning).
Case Studies
We validate the framework through six case studies spanning deep learning and mathematics. All figures below were produced autonomously by the agent and taken directly from the agent’s reports.
Optimizer Exploration for LLM Pretraining
Given a memory budget, the agent explored modifications to the Muon optimizer for LLM pretraining. It discovered that normalizing the momentum buffer and adding weight decay provide nearly additive improvements. The one-variable commandment was critical: it allowed isolating each contribution and identifying the best combination.
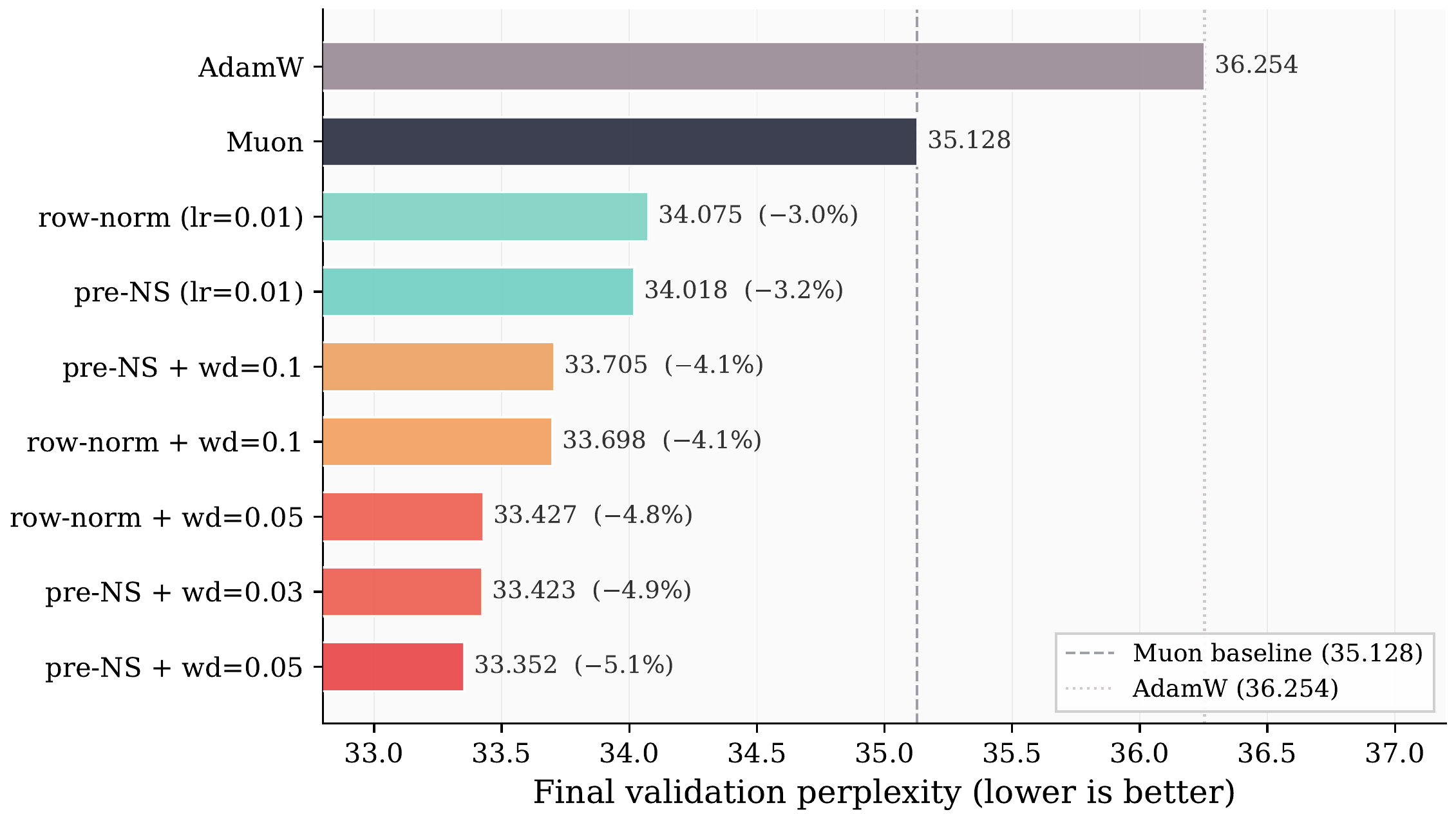
Final validation perplexity (agent-generated plot). The agent's best modification achieves ~5% improvement over Muon and ~8% over AdamW.
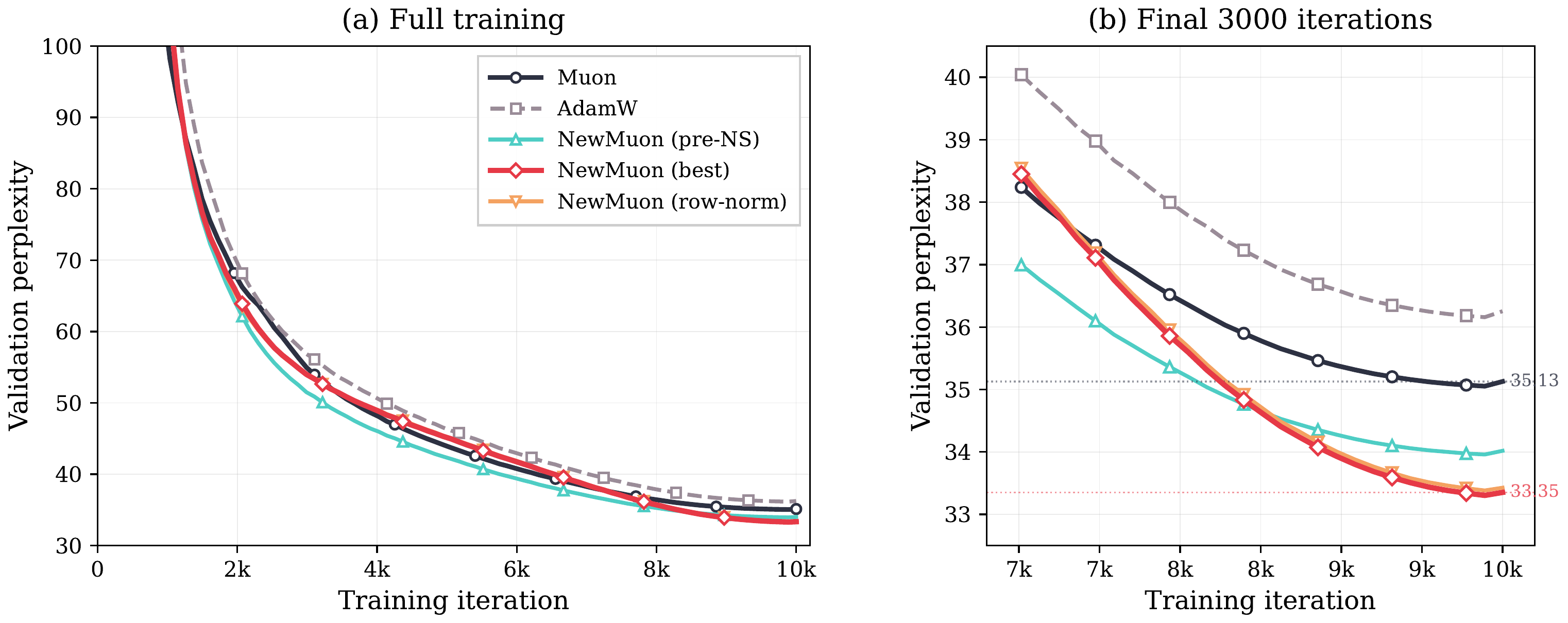
Training curves over the full run and final 3,000 iterations (agent-generated plot). The improvements are consistent throughout training.
40+ experiments over 20+ hours of autonomous operation.
Weight Reconstruction in LLM Pruning
While debugging a broken pruning algorithm, the agent observed severe activation imbalance and proposed a simple 10-line post-pruning weight correction. The method reduces perplexity by 18 to 50% across five model scales and three architectures, with less than 1% compute overhead.
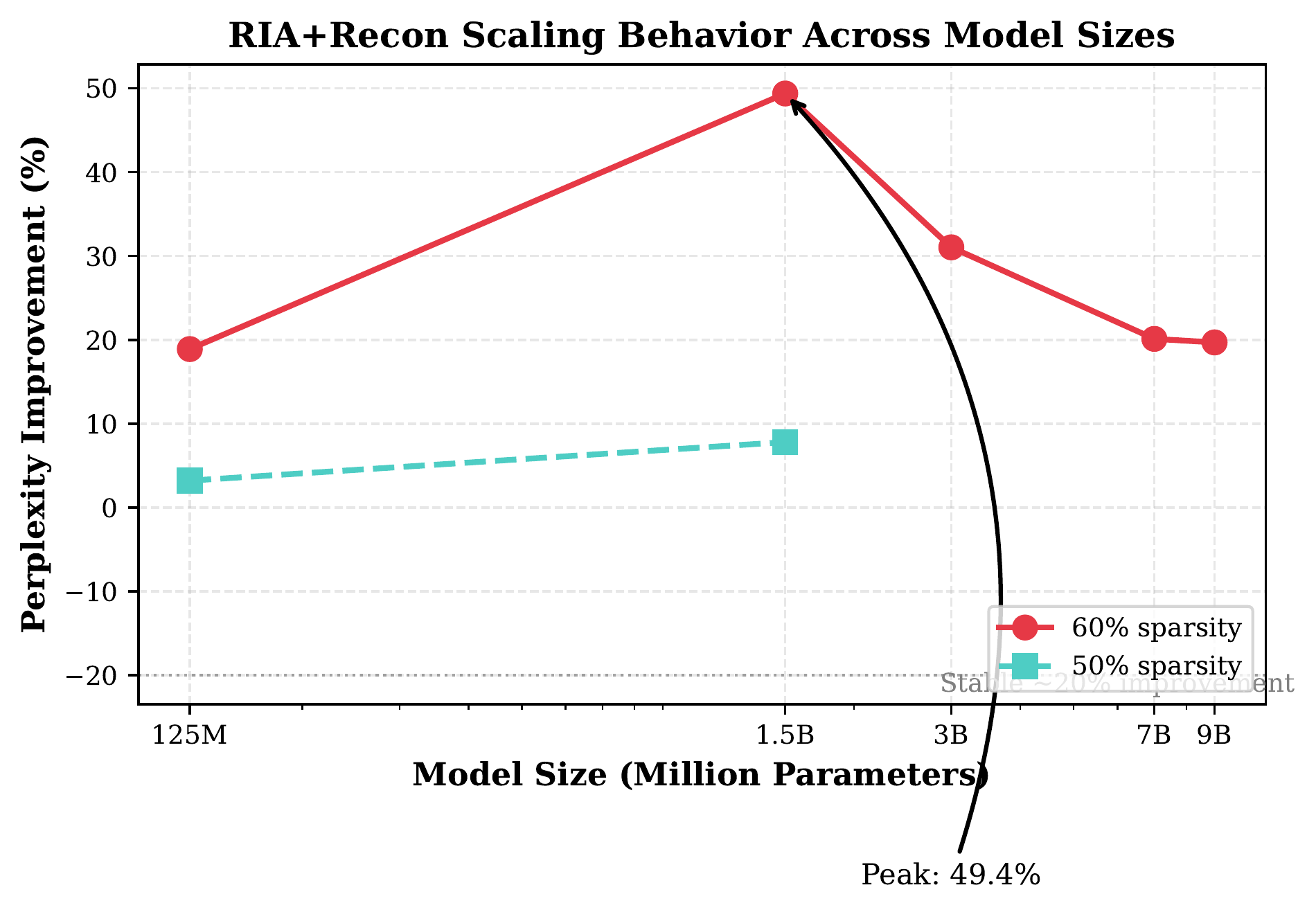
Relative perplexity improvement vs. model size (agent-generated plot). The effect peaks at 49.4% for 1.5B parameters at 60% sparsity.
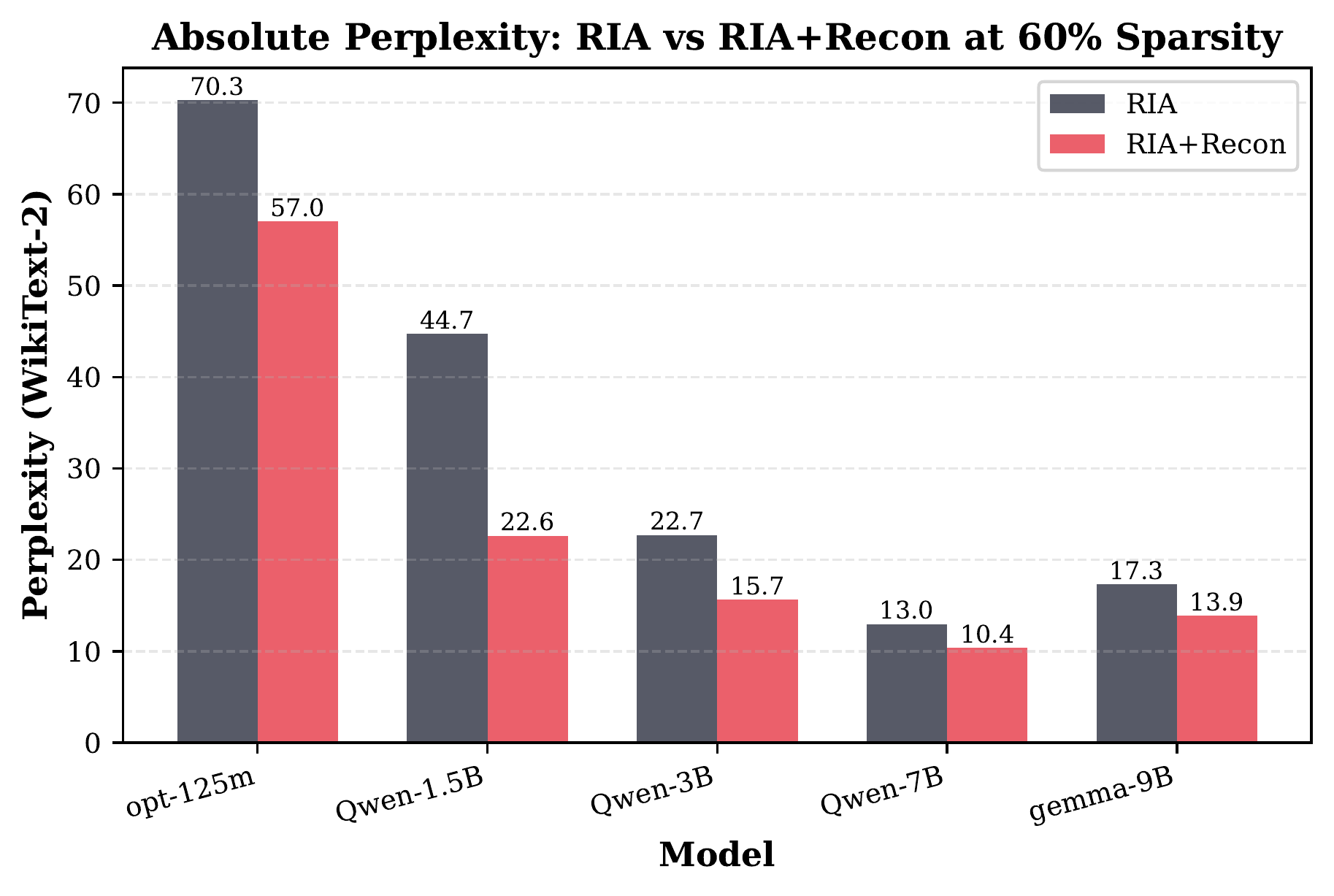
Absolute perplexity at 60% sparsity (agent-generated plot). RIA+Recon consistently outperforms the baseline across all model sizes.
Further Case Studies
Column Ordering in LLM Quantization
Investigated seven GPTQ column ordering strategies. The effect varies by two orders of magnitude across architectures (0.1% on Gemma, 74% on Llama). 9 of 24 experiments were negative results, each documented with the same rigor as positive ones.
Lower Bounds for Frank-Wolfe
Proved tight lower bounds for Frank-Wolfe on uniformly convex sets, resolving an open question. Over 30 verification scripts using BigFloat arithmetic confirmed the results to less than 0.2% relative error.
Multi-Variable Dual Tightening
Generalized dual tightening in the Boscia solver. Symbolic verification (2,387 checks) and numerical verification (487 checks) caught an inverted bound in the initial derivation, preventing incorrect conclusions.
Maximal Real Solutions in Power Networks
Characterized maximum real solutions for K7 power flow networks through systematic computational search, identifying 192 nontrivial solutions complementing theoretical approaches.
Citation
If you find this work useful, please consider citing our paper:
@article{zimmer2026agentic,
title={The Agentic Researcher: A Practical Guide to AI-Assisted Research in Mathematics and Machine Learning},
author={Max Zimmer and Nico Pelleriti and Christophe Roux and Sebastian Pokutta},
journal={arXiv preprint arXiv:2603.15914},
year={2026}
}