
Nine recurring edit types found in EvoTrace. The paper asks which edits actually help, and when a better final score hides a weaker story.
The Question
Evolutionary coding agents keep a population of candidate programs, ask a language model to modify them, run the changed code, and keep the versions that score well. This setup has produced strong results in mathematical discovery and algorithm design, but the usual headline is still just one number: the best score reached by a run.
That score alone does not tell us what happened. A run might discover a new algorithm, tune constants in an existing one, reuse an idea that was already in the prompt context, overfit to the evaluator, or repeatedly add back code it had already deleted. This paper studies the run itself: every program, prompt, score, parent-child link, and evaluator output.
EvoTrace
EvoTrace is a dataset of structured search traces from evolutionary coding systems that use language models. It covers 121 runs across four frameworks, five generator models, and 16 tasks: six Python mathematical-discovery tasks and ten C++ competitive programming problems from ALE-bench Lite.
Instead of saving only final scores, each trace saves what is needed to inspect and rerun the search: full program source, parent-child graph, prompts and context, evaluator outputs, execution logs, scores, and environment metadata.
Math Discovery
Tasks include circle packing, Heilbronn placement, autocorrelation, uncertainty inequalities, and signal-processing objectives. These runs make it easier to separate new code structure from constant tuning.
Algorithm Design
ALE-bench tasks use an external judge and private test cases. This exposes cases where public best-so-far scores do not hold up on the private evaluation.
Multiple Frameworks
OpenEvolve, GEPA, EvoX, and ShinkaEvolve are normalized into a shared schema despite different selection, diversity, prompting, and routing strategies.
Replayable Artifacts
Full source and evaluator metadata are preserved, so candidates can be re-evaluated, simplified, replayed from the same prompt, tested with another model, or retuned.
EvoReplay
EvoReplay is the tool built on top of EvoTrace. It lets us pick a point in a saved run, rebuild the local search state around it, and then rerun, simplify, retune, or rejudge the candidate program.
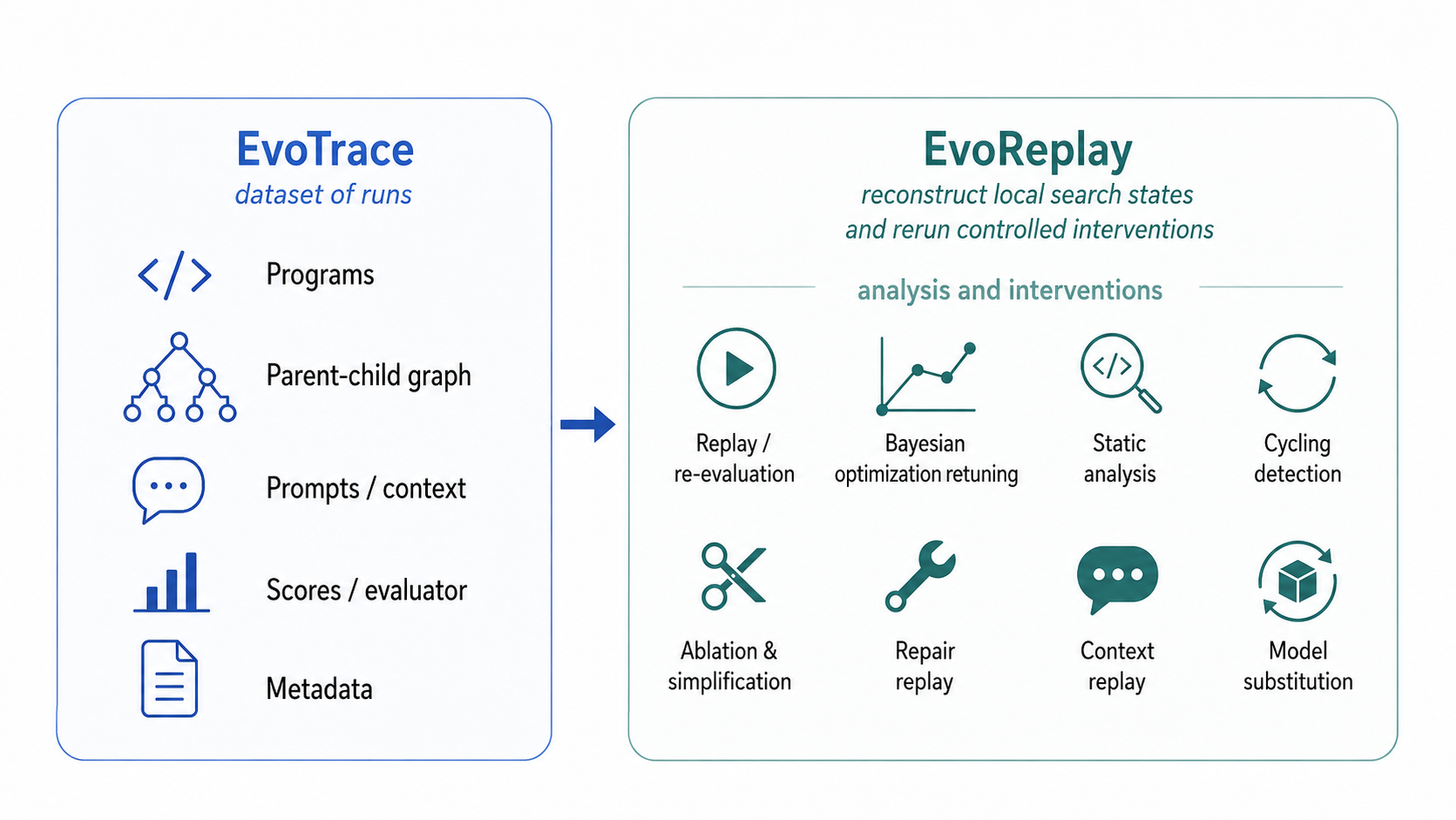
EvoTrace records programs, graphs, prompts, scores, and metadata. EvoReplay uses those records for replay, retuning, static analysis, cycling detection, repair, context replay, and model substitution.
Read the edits
Convert backend-specific traces into one parent-child edit table with scores, prompts, and diffs.
Rerun the state
Rerun prompts, substitute models or contexts, repair candidates, and ablate program components.
Check constant tuning
Retune exposed constants in a fixed program and compare that result with the evolutionary run.
Which Edits Matter?
Every parent-child edit is labeled with one or more of nine edit types. The paper uses a language-model judge for this, then checks it against blind human re-annotation on a stratified sample of 200 edits.
The edits that happen most often are not the edits that help most often. Hyperparameter tuning is the most common label, but external dependencies, efficiency improvements, and architectural changes have the strongest per-edit odds of improving the score.
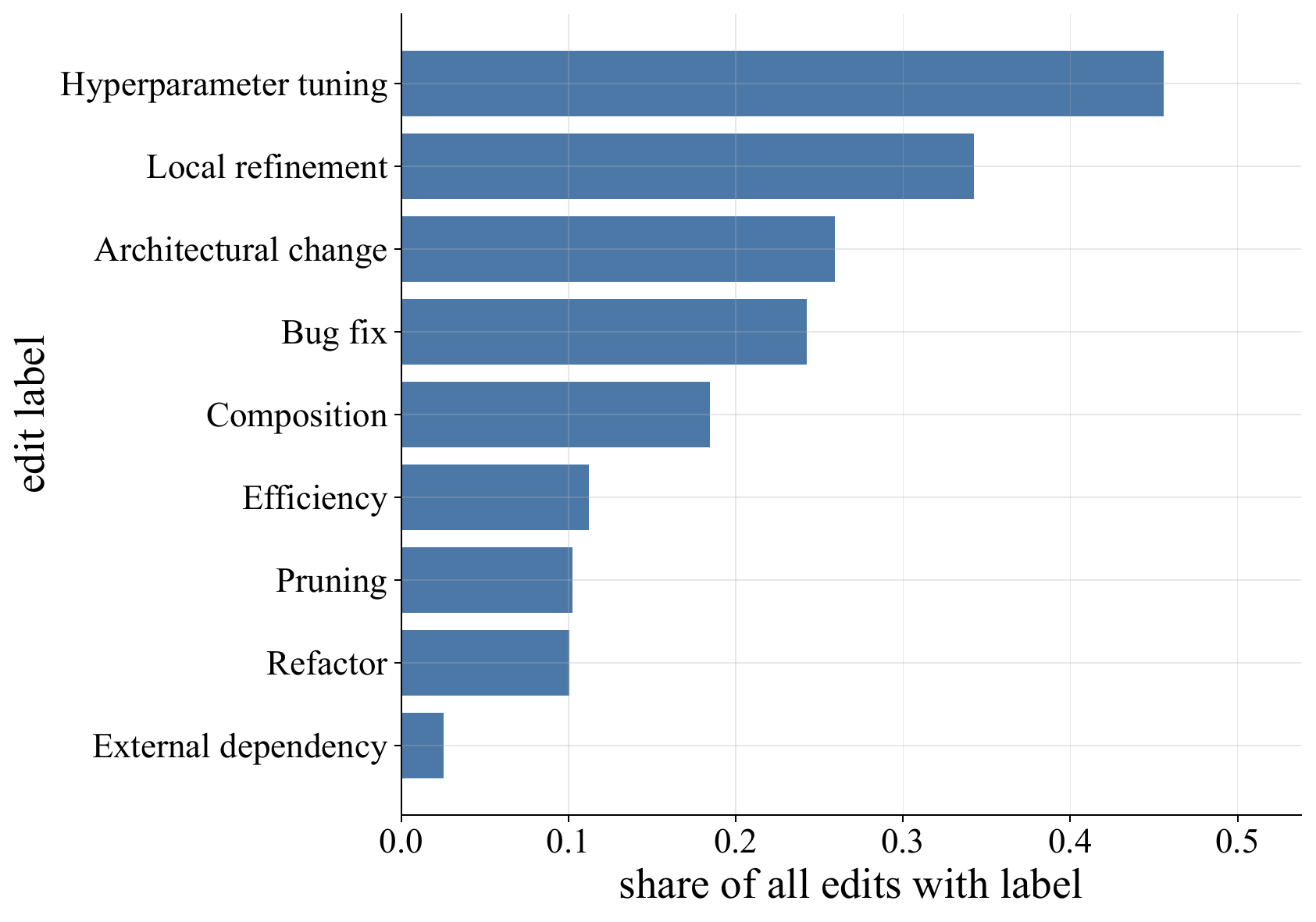
The search spends much of its effort on hyperparameter tuning and local refinement.
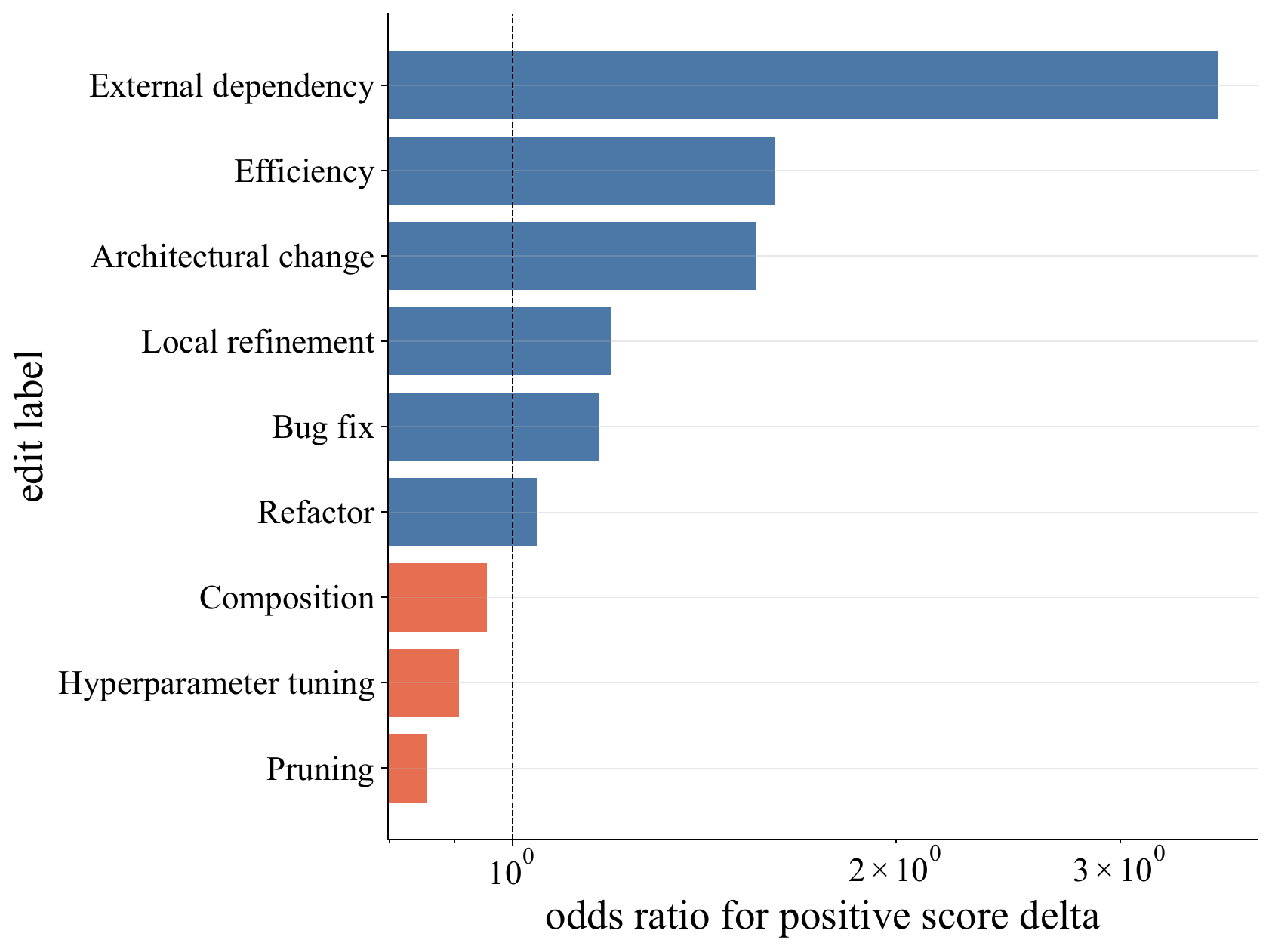
External dependencies, efficiency improvements, and architectural changes help most often per edit.
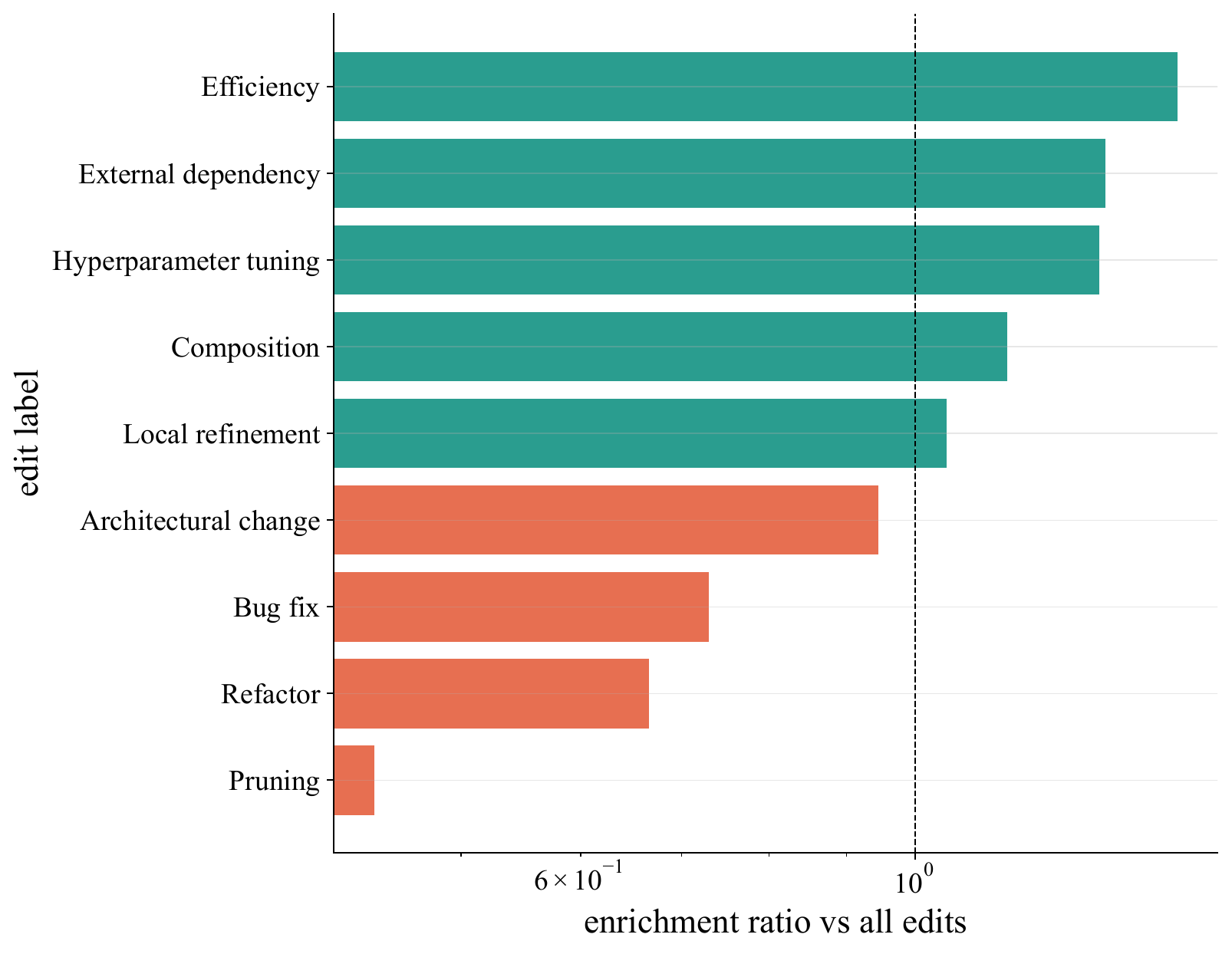
Best-so-far updates are enriched for the edit types that help, rather than simply matching the all-edits base rate.
Main Findings
Looking at the full trace changes how we read the final score. Several improvements are real, but the same score increase can come from different causes.
Rare edits drive many gains
External dependencies, efficiency improvements, and architectural changes help more often than their raw frequency would suggest.
Cycling is systematic
Across all 121 runs, about 30% of added code lines are byte-identical lines that were previously deleted in the same lineage. The cycling rate grows over the run in 118 of 121 cases.
Replays work, exact copies do not
Across 36 breakthrough events, same-prompt replays have median parse success 1.00 and evaluator success 1.00, but median exact-match rate 0.00. They still recover a median 0.76 of the original score.
Tuning explains many late wins
A 24-call Bayesian-optimization pass over constants improves 22 of 36 probed intermediate programs. It matches or exceeds the run's final best on 13 of 15 intermediate programs.
Public scores can mislead
On ALE-bench, the private-test check covers 30 run/problem pairs. Two of the four frameworks overfit on at least 30% of the problems they were scored on.
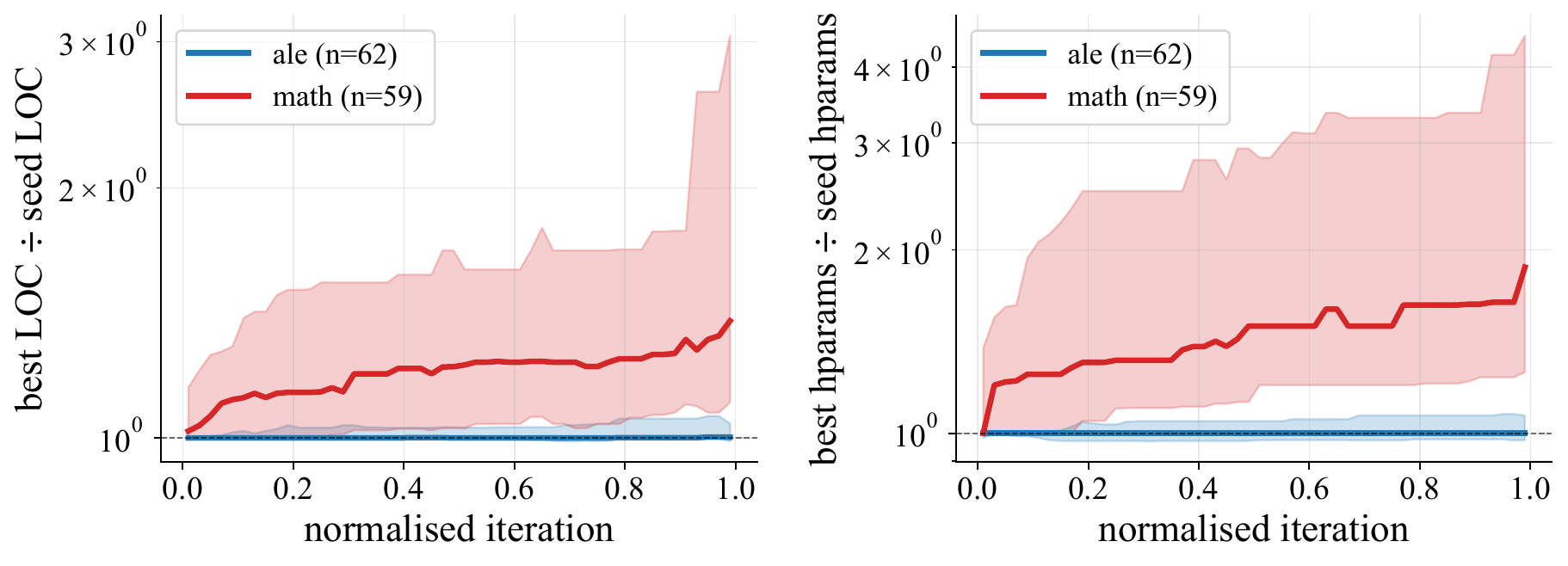
Math runs tend to accumulate modest program-size and numeric-literal growth, while ALE runs refine already-large seeds at roughly constant size.
Takeaway
Evolutionary coding agents should not be judged only by the best score they reach. The same final number can mean a new algorithm, a better constant setting, overfitting to public feedback, repeated code churn, or an old idea resurfacing from the prompt context.
EvoTrace and EvoReplay make those cases measurable. They let us ask whether a run found a new idea, whether the same prompt reliably gives a similar result, whether simple retuning would have matched it, and how much search budget is spent bringing old code back.
Citation
If you find this work useful, please consider citing our paper:
@article{pelleriti2026what,
title={What Do Evolutionary Coding Agents Evolve?},
author={Nico Pelleriti and Sree Harsha Nelaturu and Zhanke Zhou and Zongze Li and Max Zimmer and Bo Han and Sebastian Pokutta},
journal={arXiv preprint arXiv:2605.20086},
year={2026}
}