Publications tagged "ai4math"
-
 PreprintarXiv preprint arXiv:2602.06888 2026
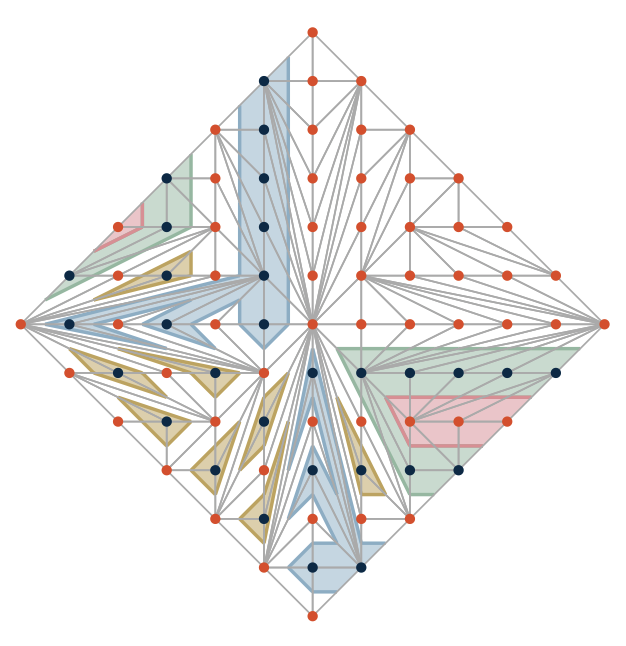
PreprintarXiv preprint arXiv:2602.06888 2026We classify all 121 real schemes of smooth real plane algebraic curves of degree seven by constructing patchworks. We provide an explicit method for constructing polynomials realizing each real scheme. The work demonstrates that every real scheme at this degree level can be realized as a T-curve, resolving a previously open question from 1996.
@article{geiselmann2026patchworked, title = {121 Patchworked Curves of Degree Seven}, author = {Geiselmann, Zoe and Joswig, Michael and Kastner, Lars and Mundinger, Konrad and Pokutta, Sebastian and Spiegel, Christoph and Wack, Marcel and Zimmer, Max}, journal = {arXiv preprint arXiv:2602.06888}, year = {2026}, } -
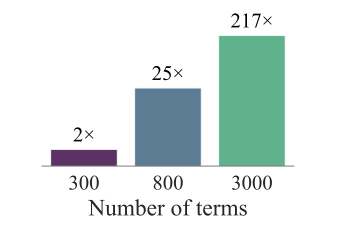 ICLR26 The Fourteenth International Conference on Learning Representations 2026
ICLR26 The Fourteenth International Conference on Learning Representations 2026Certifying nonnegativity of polynomials is a well-known NP-hard problem with direct applications spanning non-convex optimization, control, robotics, and beyond. A sufficient condition for nonnegativity is the Sum of Squares (SOS) property, i.e., it can be written as a sum of squares of other polynomials. In practice, however, certifying the SOS criterion remains computationally expensive and often involves solving a Semidefinite Program (SDP), whose dimensionality grows quadratically in the size of the monomial basis of the SOS expression; hence, various methods to reduce the size of the monomial basis have been proposed. In this work, we introduce the first learning-augmented algorithm to certify the SOS criterion. To this end, we train a Transformer model that predicts an almost-minimal monomial basis for a given polynomial, thereby drastically reducing the size of the corresponding SDP. Our overall methodology comprises three key components: efficient training dataset generation of over 100 million SOS polynomials, design and training of the corresponding Transformer architecture, and a systematic fallback mechanism to ensure correct termination, which we analyze theoretically. We validate our approach on over 200 benchmark datasets, achieving speedups of over 100× compared to state-of-the-art solvers and enabling the solution of instances where competing approaches fail. Our findings provide novel insights towards transforming the practical scalability of SOS programming.
@inproceedings{pelleriti2025neural, title = {Neural Sum-of-Squares: Certifying the Nonnegativity of Polynomials with Transformers}, author = {Pelleriti, Nico and Spiegel, Christoph and Liu, Shiwei and Mart{\'i}nez-Rubio, David and Zimmer, Max and Pokutta, Sebastian}, booktitle = {The Fourteenth International Conference on Learning Representations}, year = {2026}, } -
 H. Kera, N. Pelleriti, Y. Ishihara, M. Zimmer, and S. PokuttaNEURIPS25 Advances in Neural Information Processing Systems 2025
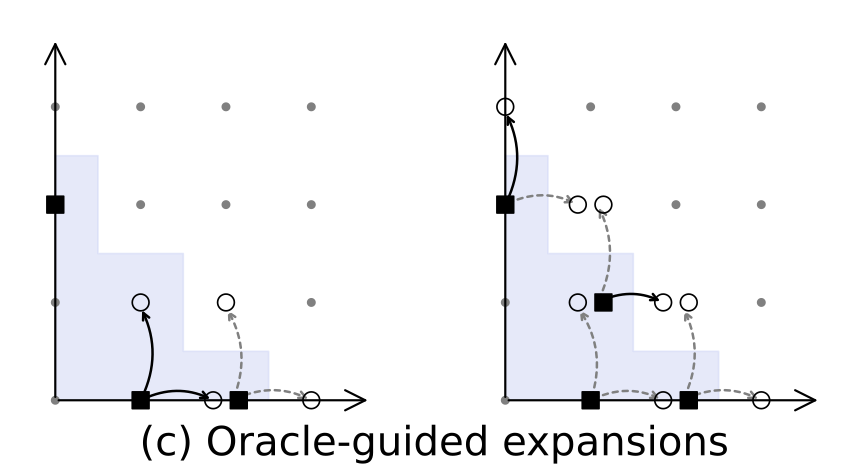
H. Kera, N. Pelleriti, Y. Ishihara, M. Zimmer, and S. PokuttaNEURIPS25 Advances in Neural Information Processing Systems 2025Solving systems of polynomial equations, particularly those with finitely many solutions, is a crucial challenge across many scientific fields. Traditional methods like Gröbner and Border bases are fundamental but suffer from high computational costs, which have motivated recent Deep Learning approaches to improve efficiency, albeit at the expense of output correctness. In this work, we introduce the Oracle Border Basis Algorithm, the first Deep Learning approach that accelerates Border basis computation while maintaining output guarantees. To this end, we design and train a Transformer-based oracle that identifies and eliminates computationally expensive reduction steps, which we find to dominate the algorithm’s runtime. By selectively invoking this oracle during critical phases of computation, we achieve substantial speedup factors of up to 3.5x compared to the base algorithm, without compromising the correctness of results. To generate the training data, we develop a sampling method and provide the first sampling theorem for border bases. We construct a tokenization and embedding scheme tailored to monomial-centered algebraic computations, resulting in a compact and expressive input representation, which reduces the number of tokens to encode an n-variate polynomial by a factor of O(n). Our learning approach is data efficient, stable, and a practical enhancement to traditional computer algebra algorithms and symbolic computation.
@inproceedings{kera2025computationalalgebraattentiontransformer, title = {Computational Algebra with Attention: Transformer Oracles for Border Basis Algorithms}, author = {Kera, Hiroshi and Pelleriti, Nico and Ishihara, Yuki and Zimmer, Max and Pokutta, Sebastian}, booktitle = {Advances in Neural Information Processing Systems}, volume = {38}, year = {2025}, } -
 ICML25 Forty-second International Conference on Machine Learning (Oral presentation, top 1%) 2025
ICML25 Forty-second International Conference on Machine Learning (Oral presentation, top 1%) 2025We demonstrate how neural networks can drive mathematical discovery through a case study of the Hadwiger-Nelson problem, a long-standing open problem from discrete geometry and combinatorics about coloring the plane avoiding monochromatic unit-distance pairs. Using neural networks as approximators, we reformulate this mixed discrete-continuous geometric coloring problem as an optimization task with a probabilistic, differentiable loss function. This enables gradient-based exploration of admissible configurations that most significantly led to the discovery of two novel six-colorings, providing the first improvements in thirty years to the off-diagonal variant of the original problem (Mundinger et al., 2024a). Here, we establish the underlying machine learning approach used to obtain these results and demonstrate its broader applicability through additional results and numerical insights.
@inproceedings{mundinger2025neural, title = {Neural Discovery in Mathematics: Do Machines Dream of Colored Planes?}, author = {Mundinger, Konrad and Zimmer, Max and Kiem, Aldo and Spiegel, Christoph and Pokutta, Sebastian}, booktitle = {Forty-second International Conference on Machine Learning}, year = {2025}, url = {https://openreview.net/forum?id=7Tp9zjP9At}, } -
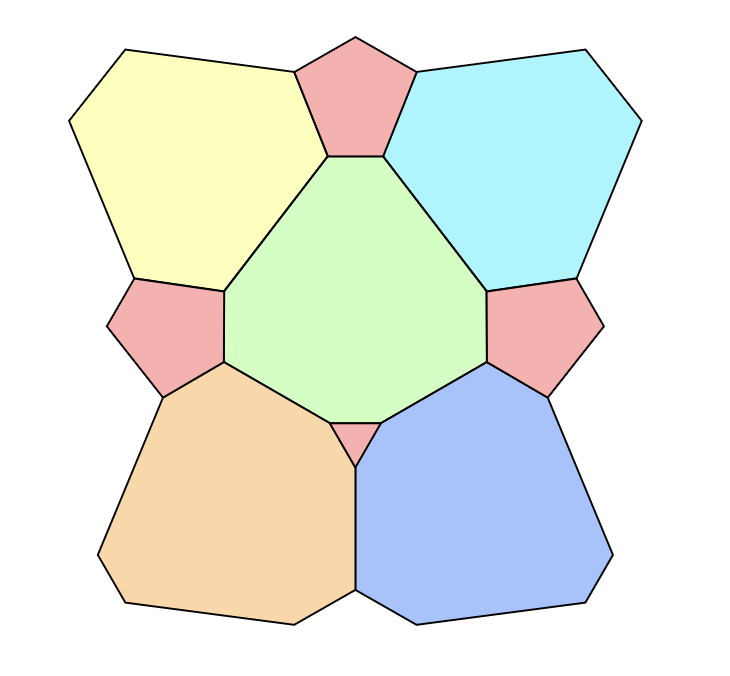 JournalGeombinatorics Quarterly 2024
JournalGeombinatorics Quarterly 2024We present two novel six-colorings of the Euclidean plane that avoid monochromatic pairs of points at unit distance in five colors and monochromatic pairs at another specified distance d in the sixth color. Such colorings have previously been known to exist for 0.41 < \sqrt2 - 1 \le d \le 1 / \sqrt5 < 0.45. Our results significantly expand that range to 0.354 \le d \le 0.657, the first improvement in 30 years. Notably, the constructions underlying this were derived by formalizing colorings suggested by a custom machine learning approach.
@article{mundinger2024extending, author = {Mundinger, Konrad and Pokutta, Sebastian and Spiegel, Christoph and Zimmer, Max}, journal = {Geombinatorics Quarterly}, title = {Extending the Continuum of Six-Colorings}, year = {2024}, volume = {XXXIV}, archiveprefix = {arXiv}, eprint = {2404.05509}, url = {https://geombina.uccs.edu/past-issues/volume-xxxiv}, } -
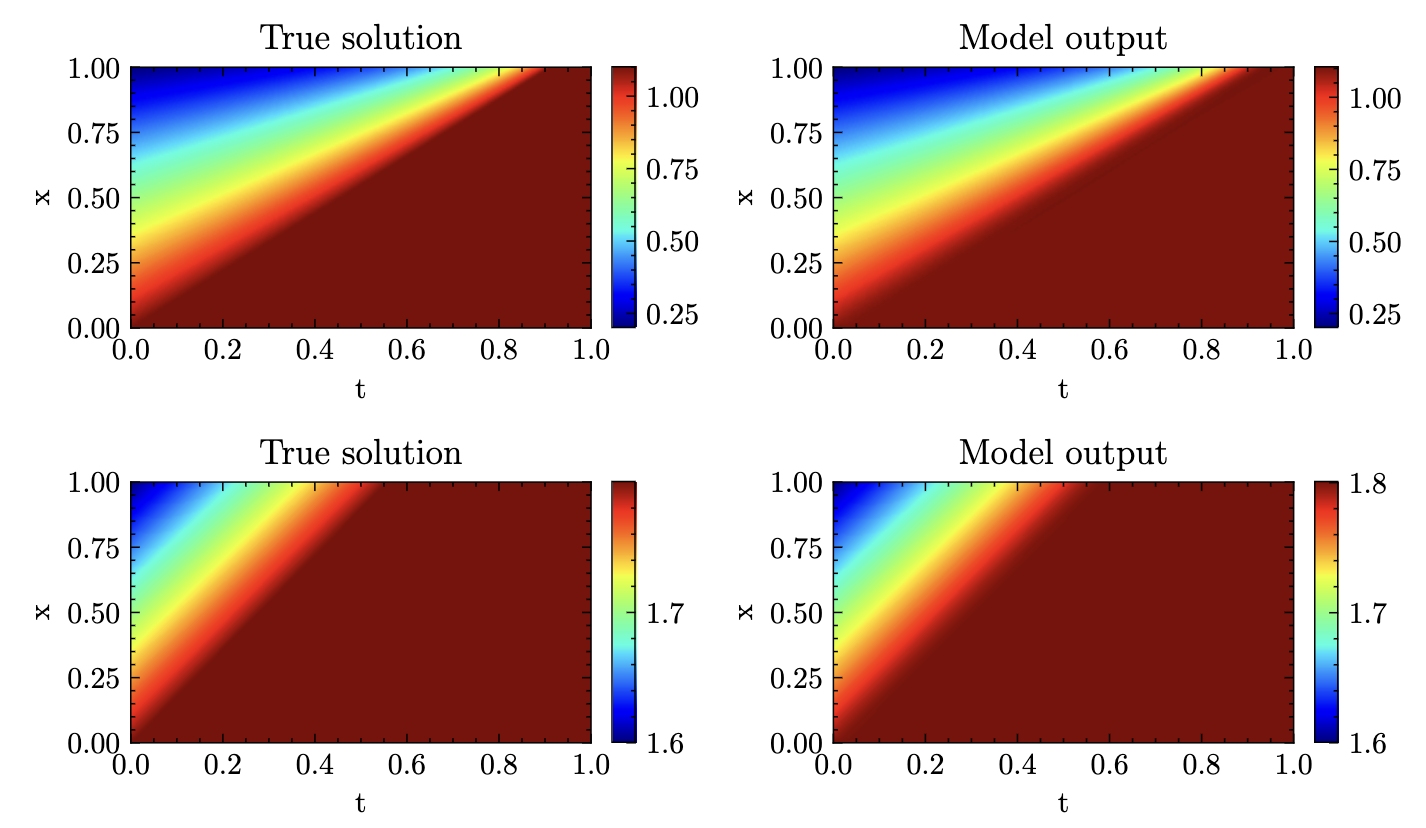 K. Mundinger, M. Zimmer, and S. PokuttaWorkshop ICLR24 Workshop on AI4DifferentialEquations In Science 2024
K. Mundinger, M. Zimmer, and S. PokuttaWorkshop ICLR24 Workshop on AI4DifferentialEquations In Science 2024We introduce Neural Parameter Regression (NPR), a novel framework specifically developed for learning solution operators in Partial Differential Equations (PDEs). Tailored for operator learning, this approach surpasses traditional DeepONets (Lu et al., 2021) by employing Physics-Informed Neural Network (PINN, Raissi et al., 2019) techniques to regress Neural Network (NN) parameters. By parametrizing each solution based on specific initial conditions, it effectively approximates a mapping between function spaces. Our method enhances parameter efficiency by incorporating low-rank matrices, thereby boosting computational efficiency and scalability. The framework shows remarkable adaptability to new initial and boundary conditions, allowing for rapid fine-tuning and inference, even in cases of out-of-distribution examples.
@inproceedings{mundinger2024neural, author = {Mundinger, Konrad and Zimmer, Max and Pokutta, Sebastian}, title = {Neural Parameter Regression for Explicit Representations of PDE Solution Operators}, year = {2024}, booktitle = {ICLR 2024 Workshop on AI4DifferentialEquations In Science}, url = {https://openreview.net/forum?id=6Z0q0dzSJQ}, }