Publications tagged "efficiency"
-
 A. Urbano, D. W. Romero, M. Zimmer, and S. PokuttaICLR26 The Fourteenth International Conference on Learning Representations 2026
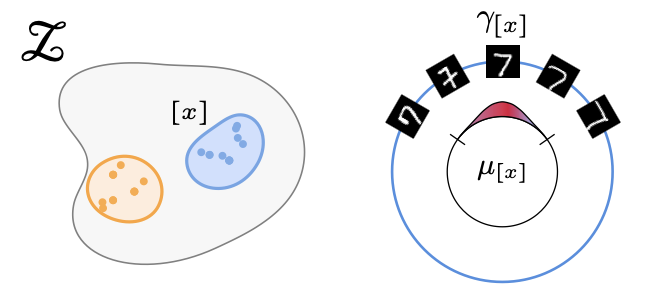
A. Urbano, D. W. Romero, M. Zimmer, and S. PokuttaICLR26 The Fourteenth International Conference on Learning Representations 2026Real-world data often exhibits unknown or approximate symmetries, yet existing equivariant networks must commit to a fixed transformation group prior to training, e.g., continuous SO(2) rotations. This mismatch degrades performance when the actual data symmetries differ from those in the transformation group. We introduce RECON, a framework to discover each input’s intrinsic symmetry distribution from unlabeled data. RECON leverages class-pose decompositions and applies a data-driven normalization to align arbitrary reference frames into a common natural pose, yielding directly comparable and interpretable symmetry descriptors. We demonstrate effective symmetry discovery on 2D image benchmarks and – for the first time – extend it to 3D transformation groups, paving the way towards more flexible equivariant modeling.
@inproceedings{urbano2025recon, title = {RECON: Robust symmetry discovery via Explicit Canonical Orientation Normalization}, author = {Urbano, Alonso and Romero, David W and Zimmer, Max and Pokutta, Sebastian}, booktitle = {The Fourteenth International Conference on Learning Representations}, year = {2026}, } -
 M. Zimmer, C. Roux, M. Wagner, D. Hendrych, and S. PokuttaPreprintarXiv preprint arXiv:2512.10922 2025
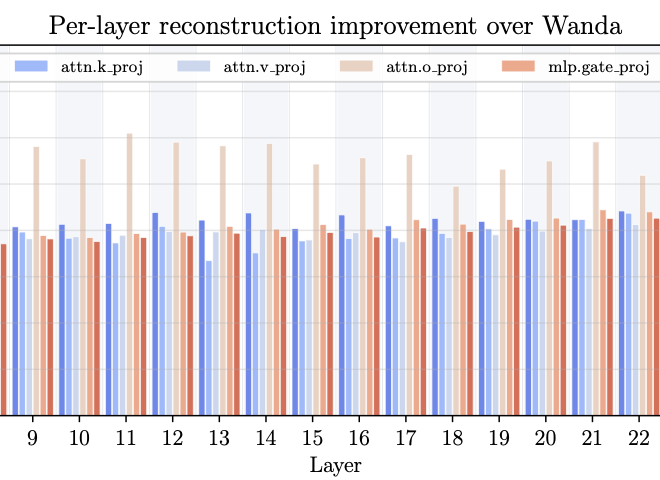
M. Zimmer, C. Roux, M. Wagner, D. Hendrych, and S. PokuttaPreprintarXiv preprint arXiv:2512.10922 2025The resource requirements of Neural Networks can be significantly reduced through pruning – the removal of seemingly less important parameters. However, with the rise of Large Language Models (LLMs), full retraining to recover pruning-induced performance degradation is often prohibitive and classical approaches such as global magnitude pruning are suboptimal on Transformer architectures. State-of-the-art methods hence solve a layer-wise mask selection problem, the problem of finding a pruning mask which minimizes the per-layer pruning error on a small set of calibration data. Exactly solving this problem to optimality using Integer Programming (IP) solvers is computationally infeasible due to its combinatorial nature and the size of the search space, and existing approaches therefore rely on approximations or heuristics. In this work, we demonstrate that the mask selection problem can be made drastically more tractable at LLM scale. To that end, we decouple the rows by enforcing equal sparsity levels per row. This allows us to derive optimal 1-swaps (exchanging one kept and one pruned weight) that can be computed efficiently using the Gram matrix of the calibration data. Using these observations, we propose a tractable and simple 1-swap algorithm that warm starts from any pruning mask, runs efficiently on GPUs at LLM scale, and is essentially hyperparameter-free. We demonstrate that our approach reduces per-layer pruning error by up to 60% over Wanda (Sun et al., 2023) and consistently improves perplexity and zero-shot accuracy across state-of-the-art GPT architectures.
@article{zimmer2025sparseswaps, title = {SparseSwaps: Tractable LLM Pruning Mask Refinement at Scale}, author = {Zimmer, Max and Roux, Christophe and Wagner, Moritz and Hendrych, Deborah and Pokutta, Sebastian}, journal = {arXiv preprint arXiv:2512.10922}, year = {2025}, } -
 M. Wagner, C. Roux, M. Zimmer, and S. PokuttaPreprintarXiv preprint arXiv:2510.14444 2025
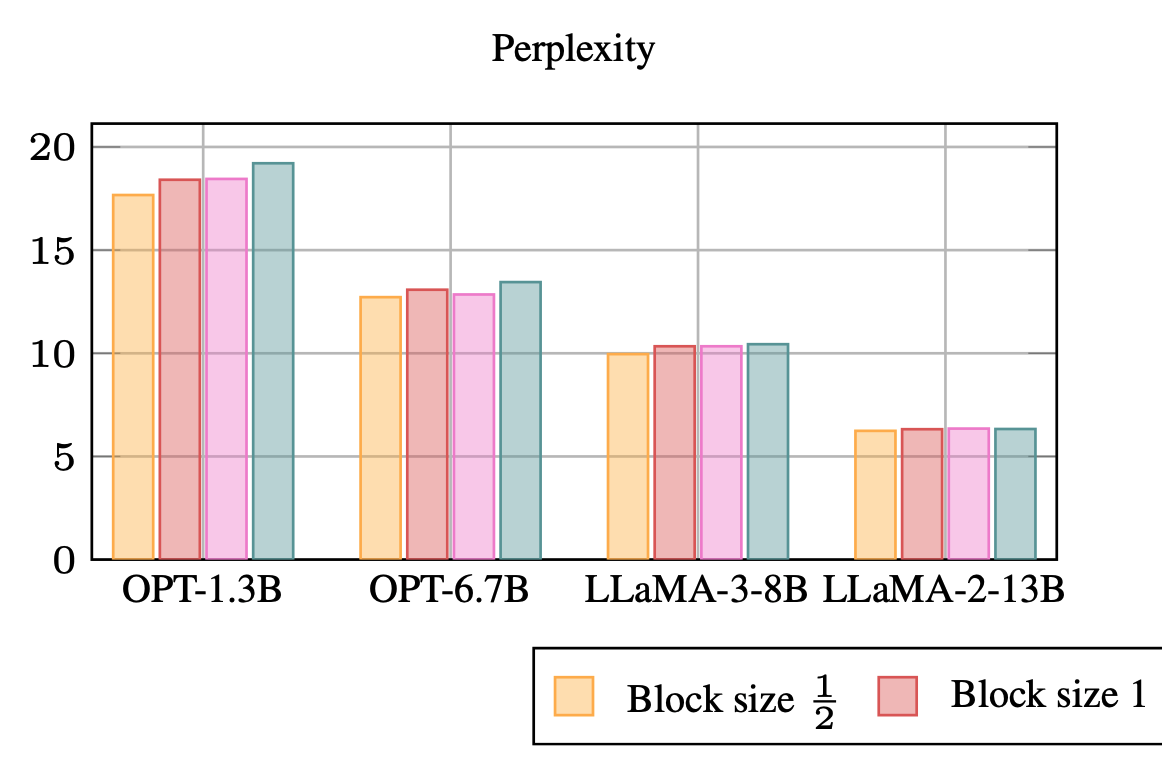
M. Wagner, C. Roux, M. Zimmer, and S. PokuttaPreprintarXiv preprint arXiv:2510.14444 2025While Neural Network pruning typically requires retraining the model to recover pruning-induced performance degradation, state-of-the-art Large Language Models (LLMs) pruning methods instead solve a layer-wise mask selection and reconstruction problem on a small set of calibration data to avoid full retraining, as it is considered computationally infeasible for LLMs. Reconstructing single matrices in isolation has favorable properties, such as convexity of the objective and significantly reduced memory requirements compared to full retraining. In practice, however, reconstruction is often implemented at coarser granularities, e.g., reconstructing a whole transformer block against its dense activations instead of a single matrix. In this work, we study the key design choices when reconstructing or retraining the remaining weights after pruning. We conduct an extensive computational study on state-of-the-art GPT architectures, and report several surprising findings that challenge common intuitions about retraining after pruning. In particular, we observe a free lunch scenario: reconstructing attention and MLP components separately within each transformer block is nearly the most resource-efficient yet achieves the best perplexity. Most importantly, this Pareto-optimal setup achieves better performance than full retraining, despite requiring only a fraction of the memory. Furthermore, we demonstrate that simple and efficient pruning criteria such as Wanda can outperform much more complex approaches when the reconstruction step is properly executed, highlighting its importance. Our findings challenge the narrative that retraining should be avoided at all costs and provide important insights into post-pruning performance recovery for LLMs.
@article{wagner2025freelunchllmcompression, title = {A Free Lunch in LLM Compression: Revisiting Retraining after Pruning}, author = {Wagner, Moritz and Roux, Christophe and Zimmer, Max and Pokutta, Sebastian}, journal = {arXiv preprint arXiv:2510.14444}, year = {2025}, } -
 C. Roux, M. Zimmer, A. d’Aspremont, and S. PokuttaPreprintarXiv preprint arXiv:2510.13713 2025
C. Roux, M. Zimmer, A. d’Aspremont, and S. PokuttaPreprintarXiv preprint arXiv:2510.13713 2025Pruning is a common technique to reduce the compute and storage requirements of Neural Networks. While conventional approaches typically retrain the model to recover pruning-induced performance degradation, state-of-the-art Large Language Model (LLM) pruning methods operate layer-wise, minimizing the per-layer pruning error on a small calibration dataset to avoid full retraining, which is considered computationally prohibitive for LLMs. However, finding the optimal pruning mask is a hard combinatorial problem and solving it to optimality is intractable. Existing methods hence rely on greedy heuristics that ignore the weight interactions in the pruning objective. In this work, we instead consider the convex relaxation of these combinatorial constraints and solve the resulting problem using the Frank-Wolfe (FW) algorithm. Our method drastically reduces the per-layer pruning error, outperforms strong baselines on state-of-the-art GPT architectures, and remains memory-efficient. We provide theoretical justification by showing that, combined with the convergence guarantees of the FW algorithm, we obtain an approximate solution to the original combinatorial problem upon rounding the relaxed solution to integrality.
@article{roux2025dontbegreedyjustrelax, title = {Don't Be Greedy, Just Relax! Pruning LLMs via Frank-Wolfe}, author = {Roux, Christophe and Zimmer, Max and d'Aspremont, Alexandre and Pokutta, Sebastian}, journal = {arXiv preprint arXiv:2510.13713}, year = {2025}, } -
 N. Pelleriti, M. Zimmer, E. Wirth, and S. PokuttaICML25 Forty-second International Conference on Machine Learning 2025
N. Pelleriti, M. Zimmer, E. Wirth, and S. PokuttaICML25 Forty-second International Conference on Machine Learning 2025Deep neural networks have reshaped modern machine learning by learning powerful latent representations that often align with the manifold hypothesis: high-dimensional data lie on lower-dimensional manifolds. In this paper, we establish a connection between manifold learning and computational algebra by demonstrating how vanishing ideals can characterize the latent manifolds of deep networks. To that end, we propose a new neural architecture that (i) truncates a pretrained network at an intermediate layer, (ii) approximates each class manifold via polynomial generators of the vanishing ideal, and (iii) transforms the resulting latent space into linearly separable features through a single polynomial layer. The resulting models have significantly fewer layers than their pretrained baselines, while maintaining comparable accuracy, achieving higher throughput, and utilizing fewer parameters. Furthermore, drawing on spectral complexity analysis, we derive sharper theoretical guarantees for generalization, showing that our approach can in principle offer tighter bounds than standard deep networks. Numerical experiments confirm the effectiveness and efficiency of the proposed approach.
@inproceedings{pelleriti2025approximatinglatentmanifoldsneural, title = {Approximating Latent Manifolds in Neural Networks via Vanishing Ideals}, author = {Pelleriti, Nico and Zimmer, Max and Wirth, Elias and Pokutta, Sebastian}, booktitle = {Forty-second International Conference on Machine Learning}, year = {2025}, url = {https://openreview.net/forum?id=WYlerYGDPL}, } -
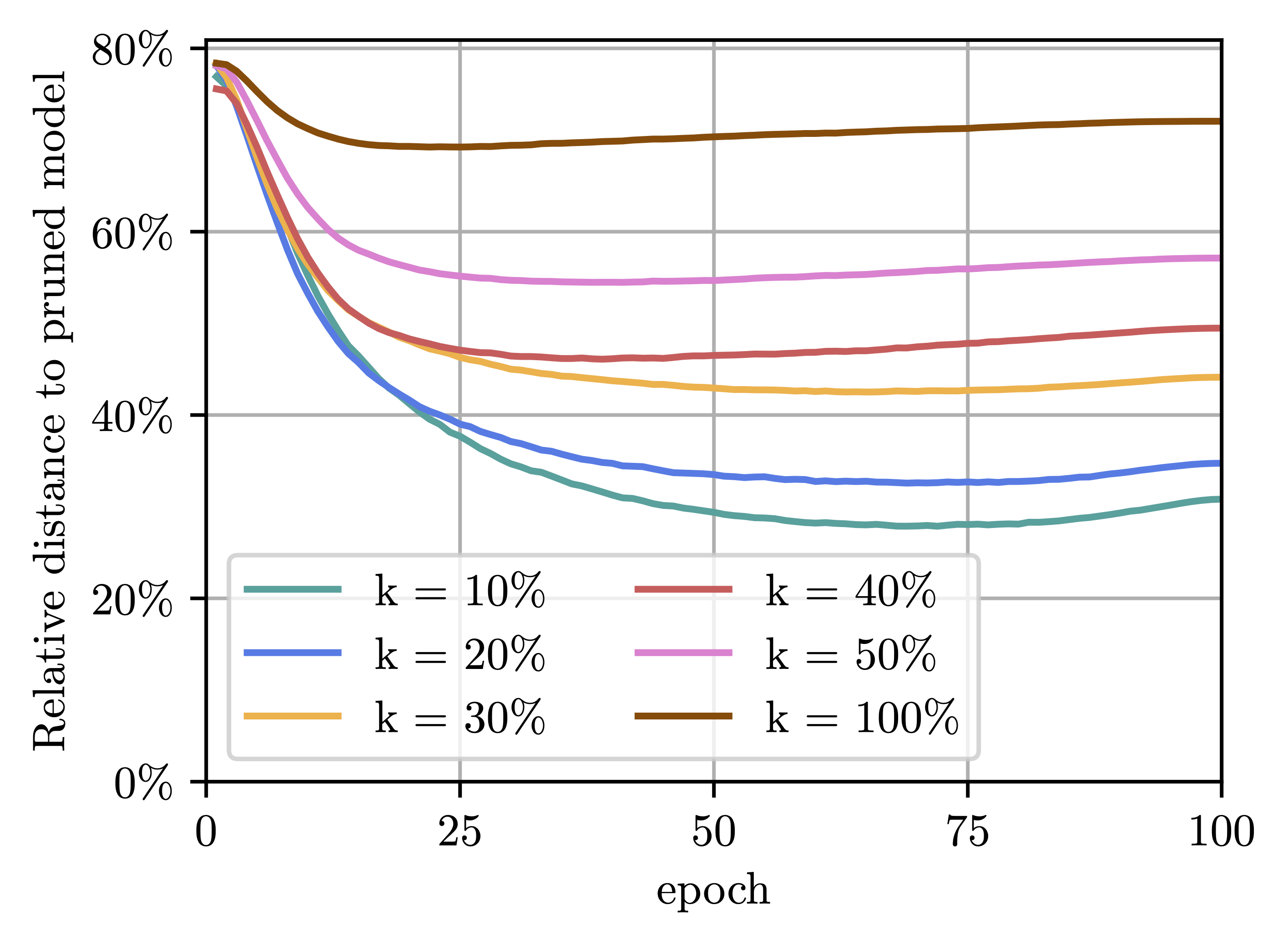 M. Zimmer, C. Spiegel, and S. PokuttaJournal Mathematical Optimization for Machine Learning 2025
M. Zimmer, C. Spiegel, and S. PokuttaJournal Mathematical Optimization for Machine Learning 2025Many existing Neural Network pruning approaches either rely on retraining to compensate for pruning-caused performance degradation or they induce strong biases to converge to a specific sparse solution throughout training. A third paradigm obtains a wide range of compression ratios from a single dense training run while also avoiding retraining. Recent work of Pokutta et al. (2020) and Miao et al. (2022) suggests that the Stochastic Frank-Wolfe (SFW) algorithm is particularly suited for training state-of-the-art models that are robust to compression. We propose leveraging k-support norm ball constraints and demonstrate significant improvements over the results of Miao et al. (2022) in the case of unstructured pruning. We also extend these ideas to the structured pruning domain and propose novel approaches to both ensure robustness to the pruning of convolutional filters as well as to low-rank tensor decompositions of convolutional layers. In the latter case, our approach performs on-par with nuclear-norm regularization baselines while requiring only half of the computational resources. Our findings also indicate that the robustness of SFW-trained models largely depends on the gradient rescaling of the learning rate and we establish a theoretical foundation for that practice.
@inbook{ZimmerSpiegelPokutta+2025+137+168, url = {https://doi.org/10.1515/9783111376776-010}, title = {Compression-aware Training of Neural Networks using Frank-Wolfe}, booktitle = {Mathematical Optimization for Machine Learning}, author = {Zimmer, Max and Spiegel, Christoph and Pokutta, Sebastian}, editor = {Fackeldey, Konstantin and Kannan, Aswin and Pokutta, Sebastian and Sharma, Kartikey and Walter, Daniel and Walther, Andrea and Weiser, Martin}, publisher = {De Gruyter}, address = {Berlin, Boston}, pages = {137--168}, doi = {doi:10.1515/9783111376776-010}, isbn = {9783111376776}, year = {2025}, } -
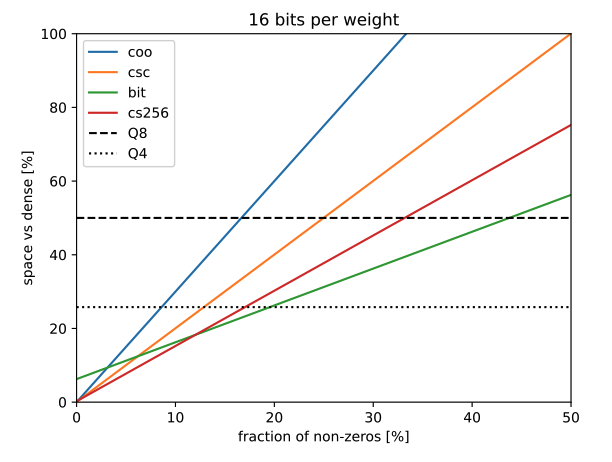 M. Lasby, M. Zimmer, S. Pokutta, and E. SchultheisWorkshop ICLR25 Workshop on Sparsity in LLMs (SLLM) 2025
M. Lasby, M. Zimmer, S. Pokutta, and E. SchultheisWorkshop ICLR25 Workshop on Sparsity in LLMs (SLLM) 2025Storing the weights of large language models (LLMs) in GPU memory for local inference is challenging due to their size. While quantization has proven successful in reducing the memory footprint of LLMs, unstructured pruning introduces overhead by requiring the non-pruned weights’ location to be encoded. This overhead hinders the efficient combination of quantization and unstructured pruning, especially for smaller batch sizes common in inference scenarios. To address this, we propose the CS256 storage format, which offers a better balance between space efficiency and hardware acceleration compared to existing formats. CS256 partitions the weight matrix into tiles and uses a hierarchical indexing scheme to locate non-zero values, reducing the overhead associated with storing sparsity patterns. Our preliminary results with one-shot pruning of LLMs show that CS256 matches the performance of unstructured sparsity while being more hardware-friendly.
@inproceedings{lasby2025compressed, title = {Compressed Sparse Tiles for Memory-Efficient Unstructured and Semi-Structured Sparsity}, author = {Lasby, Mike and Zimmer, Max and Pokutta, Sebastian and Schultheis, Erik}, booktitle = {Sparsity in LLMs (SLLM): Deep Dive into Mixture of Experts, Quantization, Hardware, and Inference}, year = {2025}, url = {https://openreview.net/forum?id=iso0KV2HVq}, } -
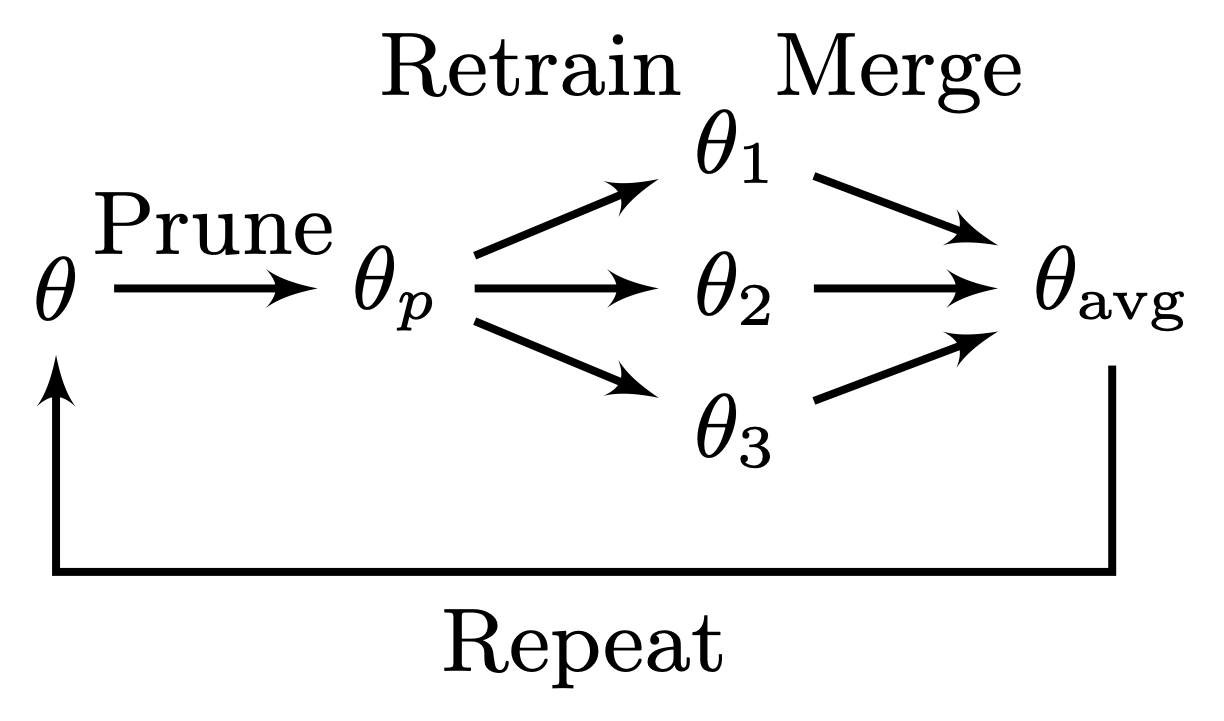 M. Zimmer, C. Spiegel, and S. PokuttaICLR24 The Twelfth International Conference on Learning Representations 2024
M. Zimmer, C. Spiegel, and S. PokuttaICLR24 The Twelfth International Conference on Learning Representations 2024Neural networks can be significantly compressed by pruning, leading to sparse models requiring considerably less storage and floating-point operations while maintaining predictive performance. Model soups (Wortsman et al., 2022) improve generalization and out-of-distribution performance by averaging the parameters of multiple models into a single one without increased inference time. However, identifying models in the same loss basin to leverage both sparsity and parameter averaging is challenging, as averaging arbitrary sparse models reduces the overall sparsity due to differing sparse connectivities. In this work, we address these challenges by demonstrating that exploring a single retraining phase of Iterative Magnitude Pruning (IMP) with varying hyperparameter configurations, such as batch ordering or weight decay, produces models that are suitable for averaging and share the same sparse connectivity by design. Averaging these models significantly enhances generalization performance compared to their individual components. Building on this idea, we introduce Sparse Model Soups (SMS), a novel method for merging sparse models by initiating each prune-retrain cycle with the averaged model of the previous phase. SMS maintains sparsity, exploits sparse network benefits being modular and fully parallelizable, and substantially improves IMP’s performance. Additionally, we demonstrate that SMS can be adapted to enhance the performance of state-of-the-art pruning during training approaches.
@inproceedings{zimmer2023sparse, title = {Sparse Model Soups: A Recipe for Improved Pruning via Model Averaging}, author = {Zimmer, Max and Spiegel, Christoph and Pokutta, Sebastian}, booktitle = {The Twelfth International Conference on Learning Representations}, year = {2024}, } -
 M. Zimmer, M. Andoni, C. Spiegel, and S. PokuttaPreprintarXiv preprint arXiv:2312.15230 2023
M. Zimmer, M. Andoni, C. Spiegel, and S. PokuttaPreprintarXiv preprint arXiv:2312.15230 2023Neural Networks can be effectively compressed through pruning, significantly reducing storage and compute demands while maintaining predictive performance. Simple yet effective methods like magnitude pruning remove less important parameters and typically require a costly retraining procedure to restore performance. However, with the rise of LLMs, full retraining has become infeasible due to memory and compute constraints. This study challenges the practice of retraining all parameters by showing that updating a small subset of highly expressive parameters can suffice to recover or even enhance performance after pruning. Surprisingly, retraining just 0.01%-0.05% of the parameters in GPT-architectures can match the performance of full retraining across various sparsity levels, significantly reducing compute and memory requirements, and enabling retraining of models with up to 30 billion parameters on a single GPU in minutes. To bridge the gap to full retraining in the high sparsity regime, we introduce two novel LoRA variants that, unlike standard LoRA, allow merging adapters back without compromising sparsity. Going a step further, we show that these methods can be applied for memory-efficient layer-wise reconstruction, significantly enhancing state-of-the-art retraining-free methods like Wanda (Sun et al., 2023) and SparseGPT (Frantar & Alistarh, 2023). Our findings present a promising alternative to avoiding retraining.
@article{zimmer2023perp, author = {Zimmer, Max and Andoni, Megi and Spiegel, Christoph and Pokutta, Sebastian}, title = {PERP: Rethinking the Prune-Retrain Paradigm in the Era of LLMs}, year = {2023}, journal = {arXiv preprint arXiv:2312.15230}, } -
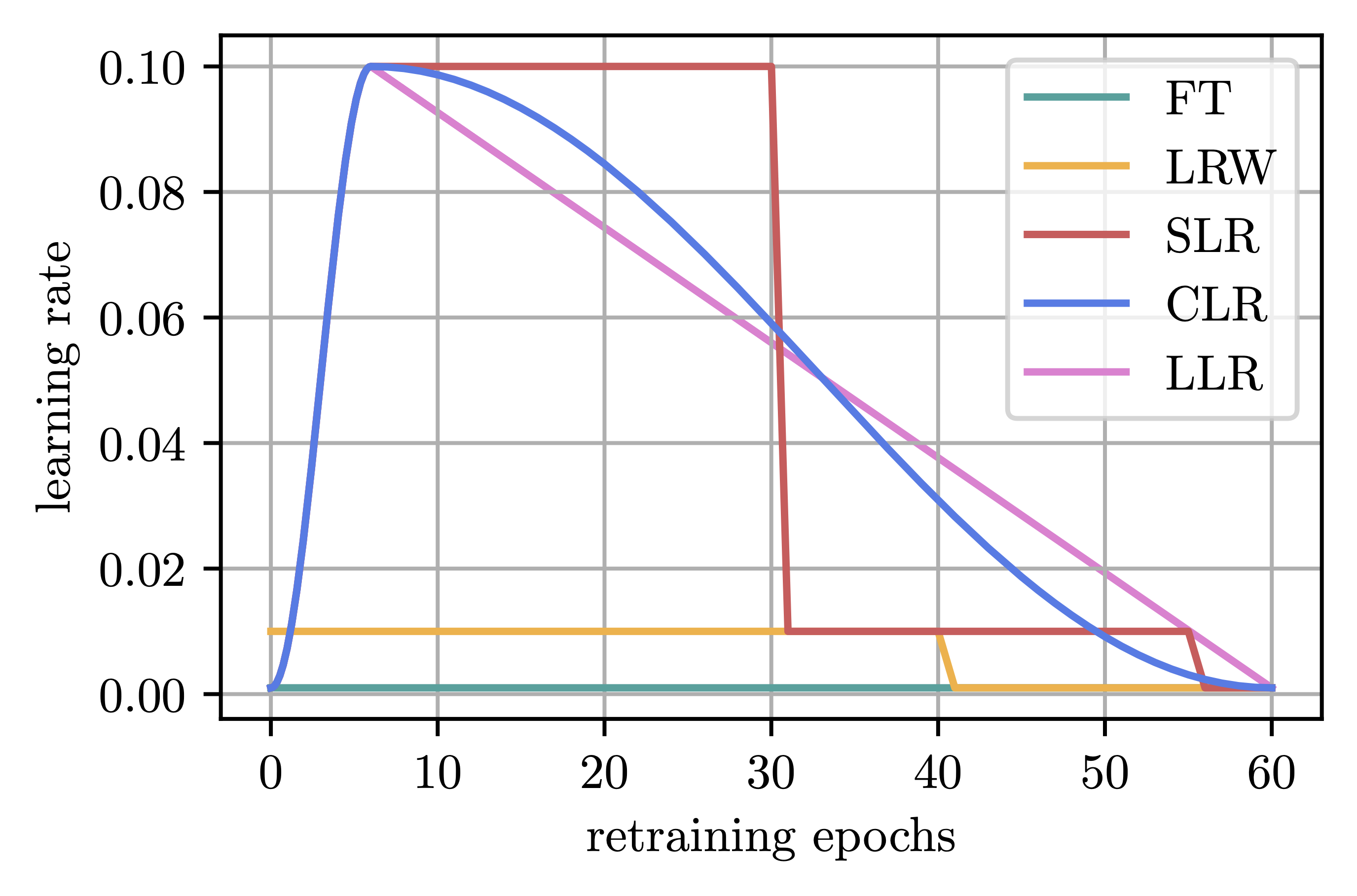 M. Zimmer, C. Spiegel, and S. PokuttaICLR23 The Eleventh International Conference on Learning Representations 2023
M. Zimmer, C. Spiegel, and S. PokuttaICLR23 The Eleventh International Conference on Learning Representations 2023Many Neural Network Pruning approaches consist of several iterative training and pruning steps, seemingly losing a significant amount of their performance after pruning and then recovering it in the subsequent retraining phase. Recent works of Renda et al. (2020) and Le & Hua (2021) demonstrate the significance of the learning rate schedule during the retraining phase and propose specific heuristics for choosing such a schedule for IMP (Han et al., 2015). We place these findings in the context of the results of Li et al. (2020) regarding the training of models within a fixed training budget and demonstrate that, consequently, the retraining phase can be massively shortened using a simple linear learning rate schedule. Improving on existing retraining approaches, we additionally propose a method to adaptively select the initial value of the linear schedule. Going a step further, we propose similarly imposing a budget on the initial dense training phase and show that the resulting simple and efficient method is capable of outperforming significantly more complex or heavily parameterized state-of-the-art approaches that attempt to sparsify the network during training. These findings not only advance our understanding of the retraining phase, but more broadly question the belief that one should aim to avoid the need for retraining and reduce the negative effects of ‘hard’ pruning by incorporating the sparsification process into the standard training.
@inproceedings{Zimmer2023, author = {Zimmer, Max and Spiegel, Christoph and Pokutta, Sebastian}, booktitle = {The Eleventh International Conference on Learning Representations}, title = {{H}ow {I} {L}earned {T}o {S}top {W}orrying {A}nd {L}ove {R}etraining}, year = {2023}, url = {https://openreview.net/forum?id=_nF5imFKQI}, }