publications
list of all my publications - you can filter by tag.
-
 D. Muhtar, X. Song, S. Pokutta, M. Zimmer, N. Pelleriti, and 2 more authorsWorkshop ICLR26 Workshop on Deep Generative Models in ML 2026
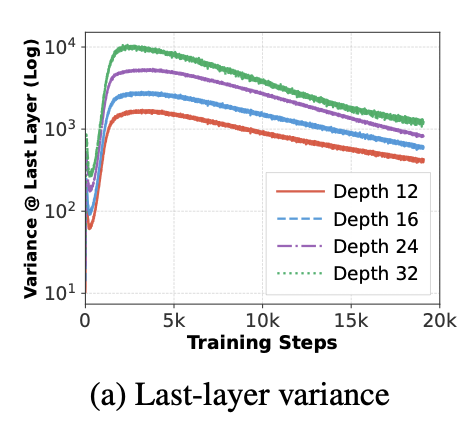
D. Muhtar, X. Song, S. Pokutta, M. Zimmer, N. Pelleriti, and 2 more authorsWorkshop ICLR26 Workshop on Deep Generative Models in ML 2026Recent work has demonstrated the curse of depth in large language models (LLMs), where later layers contribute less to learning and representation than earlier layers. Such under-utilization is linked to the accumulated growth of variance in Pre-Layer Normalization, which can push deep blocks toward near-identity behavior. In this paper, we demonstrate that, sparsity, beyond enabling efficiency, acts as a regulator of variance propagation and thereby improves depth utilization. Our investigation covers two sources of sparsity: (i) implicit sparsity, which emerges from training and data conditions, including weight sparsity induced by weight decay and attention sparsity induced by long-context inputs; and (ii) explicit sparsity, which is enforced by architectural design, including key/value-sharing sparsity in Grouped-Query Attention and expert-activation sparsity in Mixture-of-Experts. Our claim is thoroughly supported by controlled depth-scaling experiments and targeted layer effectiveness interventions. Across settings, we observe a consistent relationship: sparsity improves layer utilization by reducing output variance and promoting functional differentiation. We eventually distill our findings into a practical rule-of-thumb recipe for training depth-effective LLMs, yielding a notable 4.6% accuracy improvement on downstream tasks. Our results reveal sparsity, arising naturally from standard design choices, as a key yet previously overlooked mechanism for effective depth scaling in LLMs.
@inproceedings{muhtar2026when, title = {When Does Sparsity Mitigate the Curse of Depth in {LLM}s}, author = {Muhtar, Dilxat and Song, Xinyuan and Pokutta, Sebastian and Zimmer, Max and Pelleriti, Nico and Hofmann, Thomas and Liu, Shiwei}, booktitle = {ICLR 2026 2nd Workshop on Deep Generative Model in Machine Learning: Theory, Principle and Efficacy}, year = {2026}, url = {https://openreview.net/forum?id=trYJ2pwR0G}, } -
 PreprintarXiv preprint arXiv:2602.21421 2026
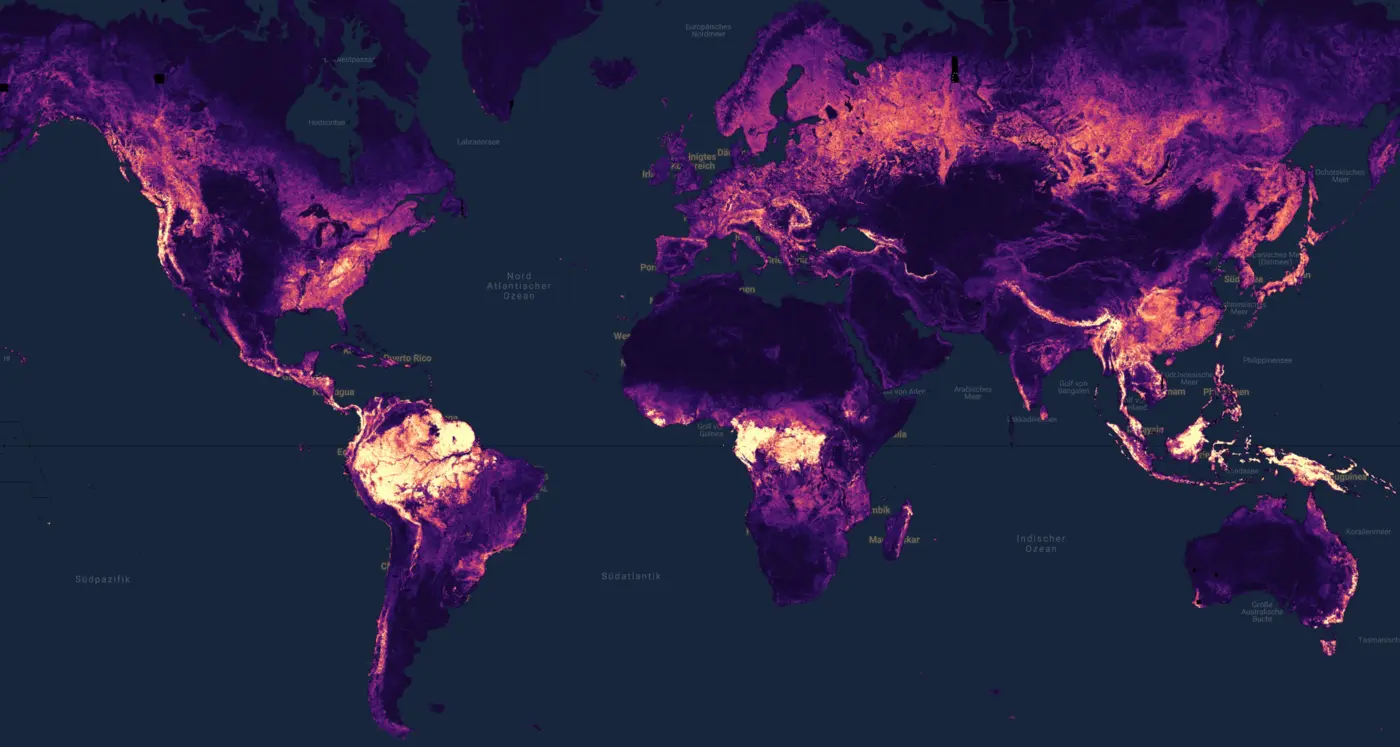
PreprintarXiv preprint arXiv:2602.21421 2026Forest monitoring is critical for climate change mitigation. However, existing global tree height maps provide only static snapshots and do not capture temporal forest dynamics, which are essential for accurate carbon accounting. We introduce ECHOSAT, a global and temporally consistent tree height map at 10 m resolution spanning multiple years. To this end, we resort to multi-sensor satellite data to train a specialized vision transformer model, which performs pixel-level temporal regression. A self-supervised growth loss regularizes the predictions to follow growth curves that are in line with natural tree development, including gradual height increases over time, but also abrupt declines due to forest loss events such as fires. Our experimental evaluation shows that our model improves state-of-the-art accuracies in the context of single-year predictions. We also provide the first global-scale height map that accurately quantifies tree growth and disturbances over time. We expect ECHOSAT to advance global efforts in carbon monitoring and disturbance assessment.
@article{pauls2026echosat, title = {ECHOSAT: Estimating Canopy Height Over Space And Time}, author = {Pauls, Jan and Schr{\"o}dter, Karsten and Ligensa, Sven and Schwartz, Martin and Turan, Berkant and Zimmer, Max and Saatchi, Sassan and Pokutta, Sebastian and Ciais, Philippe and Gieseke, Fabian}, journal = {arXiv preprint arXiv:2602.21421}, year = {2026}, } -
 PreprintarXiv preprint arXiv:2602.06888 2026
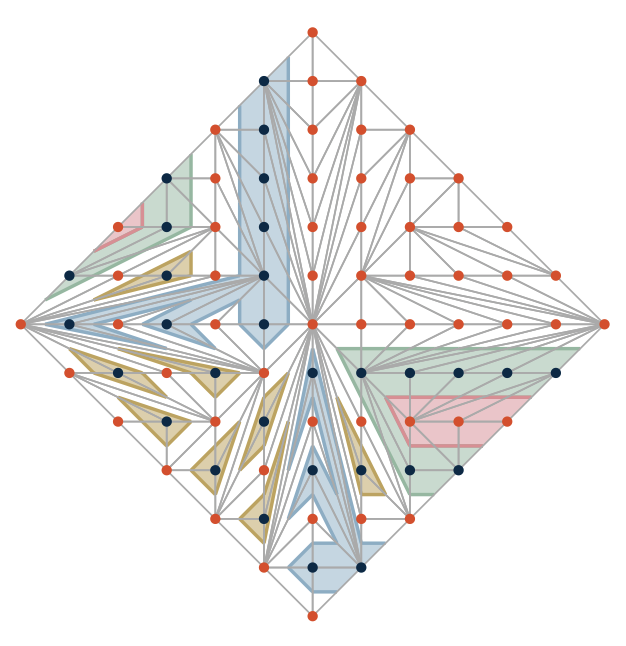
PreprintarXiv preprint arXiv:2602.06888 2026We classify all 121 real schemes of smooth real plane algebraic curves of degree seven by constructing patchworks. We provide an explicit method for constructing polynomials realizing each real scheme. The work demonstrates that every real scheme at this degree level can be realized as a T-curve, resolving a previously open question from 1996.
@article{geiselmann2026patchworked, title = {121 Patchworked Curves of Degree Seven}, author = {Geiselmann, Zoe and Joswig, Michael and Kastner, Lars and Mundinger, Konrad and Pokutta, Sebastian and Spiegel, Christoph and Wack, Marcel and Zimmer, Max}, journal = {arXiv preprint arXiv:2602.06888}, year = {2026}, } -
 PreprintarXiv preprint arXiv:2602.00628 2026
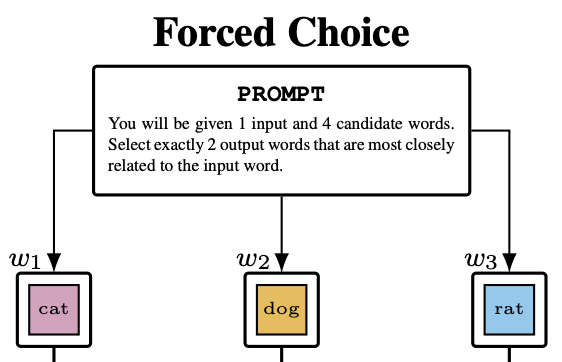
PreprintarXiv preprint arXiv:2602.00628 2026We investigate the extent to which an LLM’s hidden-state geometry can be recovered from its behavior in psycholinguistic experiments. Across eight instruction-tuned transformer models, we run two experimental paradigms – similarity-based forced choice and free association – over a shared 5,000-word vocabulary, collecting 17.5M+ trials to build behavior-based similarity matrices. Using representational similarity analysis, we compare behavioral geometries to layerwise hidden-state similarity and benchmark against FastText, BERT, and cross-model consensus. We find that forced-choice behavior aligns substantially more with hidden-state geometry than free association. In a held-out-words regression, behavioral similarity (especially forced choice) predicts unseen hidden-state similarities beyond lexical baselines and cross-model consensus, indicating that behavior-only measurements retain recoverable information about internal semantic geometry. Finally, we discuss implications for the ability of behavioral tasks to uncover hidden cognitive states.
@article{schiekiera2026associations, title = {From Associations to Activations: Comparing Behavioral and Hidden-State Semantic Geometry in LLMs}, author = {Schiekiera, Louis and Zimmer, Max and Roux, Christophe and Pokutta, Sebastian and G{\"u}nther, Fritz}, journal = {arXiv preprint arXiv:2602.00628}, year = {2026}, } -
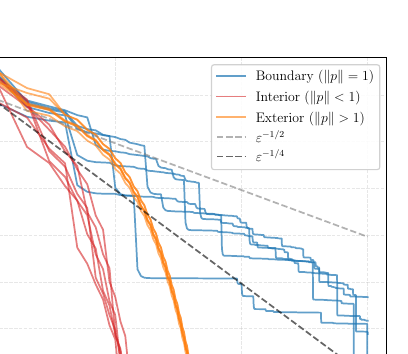 J. Halbey, D. Deza, M. Zimmer, C. Roux, B. Stellato, and 1 more authorPreprintarXiv preprint arXiv:2602.04378 2026
J. Halbey, D. Deza, M. Zimmer, C. Roux, B. Stellato, and 1 more authorPreprintarXiv preprint arXiv:2602.04378 2026We present a constructive lower bound demonstrating that Frank-Wolfe optimization requires Ω(1/√ε) iterations when both the objective function and constraint set possess smoothness and strong convexity. This result confirms that existing convergence guarantees of O(1/√ε) are optimal. We focus on a representative problem: minimizing a strongly convex quadratic over a Euclidean unit ball with the optimizer positioned at the boundary. We introduce a novel computational method for constructing worst-case trajectories and provide an analytical proof establishing our theoretical bound.
@article{halbey2026lower, title = {Lower Bounds for Frank-Wolfe on Strongly Convex Sets}, author = {Halbey, Jannis and Deza, Daniel and Zimmer, Max and Roux, Christophe and Stellato, Bartolomeo and Pokutta, Sebastian}, journal = {arXiv preprint arXiv:2602.04378}, year = {2026}, } -
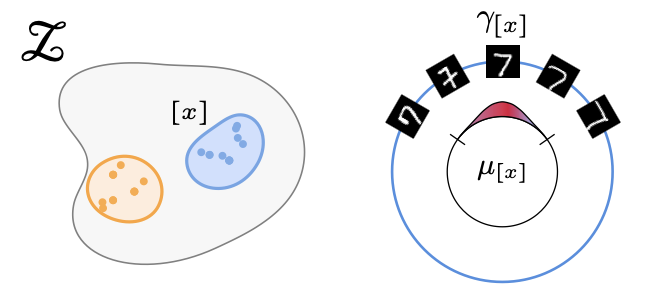 A. Urbano, D. W. Romero, M. Zimmer, and S. PokuttaICLR26 The Fourteenth International Conference on Learning Representations 2026
A. Urbano, D. W. Romero, M. Zimmer, and S. PokuttaICLR26 The Fourteenth International Conference on Learning Representations 2026Real-world data often exhibits unknown or approximate symmetries, yet existing equivariant networks must commit to a fixed transformation group prior to training, e.g., continuous SO(2) rotations. This mismatch degrades performance when the actual data symmetries differ from those in the transformation group. We introduce RECON, a framework to discover each input’s intrinsic symmetry distribution from unlabeled data. RECON leverages class-pose decompositions and applies a data-driven normalization to align arbitrary reference frames into a common natural pose, yielding directly comparable and interpretable symmetry descriptors. We demonstrate effective symmetry discovery on 2D image benchmarks and – for the first time – extend it to 3D transformation groups, paving the way towards more flexible equivariant modeling.
@inproceedings{urbano2025recon, title = {RECON: Robust symmetry discovery via Explicit Canonical Orientation Normalization}, author = {Urbano, Alonso and Romero, David W and Zimmer, Max and Pokutta, Sebastian}, booktitle = {The Fourteenth International Conference on Learning Representations}, year = {2026}, } -
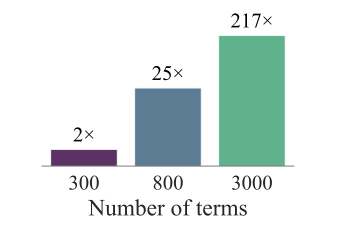 ICLR26 The Fourteenth International Conference on Learning Representations 2026
ICLR26 The Fourteenth International Conference on Learning Representations 2026Certifying nonnegativity of polynomials is a well-known NP-hard problem with direct applications spanning non-convex optimization, control, robotics, and beyond. A sufficient condition for nonnegativity is the Sum of Squares (SOS) property, i.e., it can be written as a sum of squares of other polynomials. In practice, however, certifying the SOS criterion remains computationally expensive and often involves solving a Semidefinite Program (SDP), whose dimensionality grows quadratically in the size of the monomial basis of the SOS expression; hence, various methods to reduce the size of the monomial basis have been proposed. In this work, we introduce the first learning-augmented algorithm to certify the SOS criterion. To this end, we train a Transformer model that predicts an almost-minimal monomial basis for a given polynomial, thereby drastically reducing the size of the corresponding SDP. Our overall methodology comprises three key components: efficient training dataset generation of over 100 million SOS polynomials, design and training of the corresponding Transformer architecture, and a systematic fallback mechanism to ensure correct termination, which we analyze theoretically. We validate our approach on over 200 benchmark datasets, achieving speedups of over 100× compared to state-of-the-art solvers and enabling the solution of instances where competing approaches fail. Our findings provide novel insights towards transforming the practical scalability of SOS programming.
@inproceedings{pelleriti2025neural, title = {Neural Sum-of-Squares: Certifying the Nonnegativity of Polynomials with Transformers}, author = {Pelleriti, Nico and Spiegel, Christoph and Liu, Shiwei and Mart{\'i}nez-Rubio, David and Zimmer, Max and Pokutta, Sebastian}, booktitle = {The Fourteenth International Conference on Learning Representations}, year = {2026}, } -
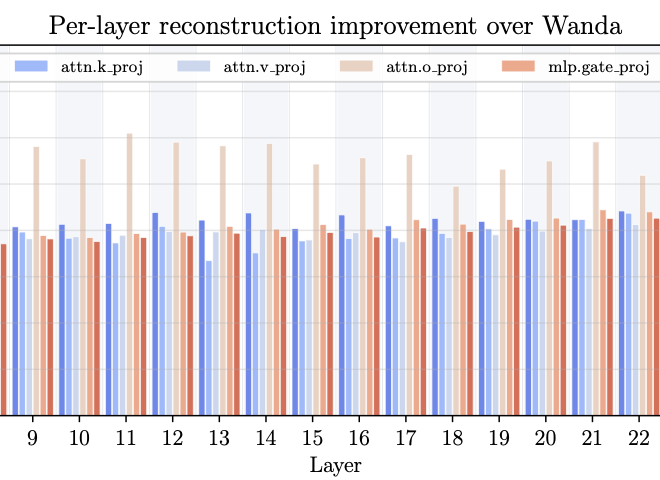 M. Zimmer, C. Roux, M. Wagner, D. Hendrych, and S. PokuttaPreprintarXiv preprint arXiv:2512.10922 2025
M. Zimmer, C. Roux, M. Wagner, D. Hendrych, and S. PokuttaPreprintarXiv preprint arXiv:2512.10922 2025The resource requirements of Neural Networks can be significantly reduced through pruning – the removal of seemingly less important parameters. However, with the rise of Large Language Models (LLMs), full retraining to recover pruning-induced performance degradation is often prohibitive and classical approaches such as global magnitude pruning are suboptimal on Transformer architectures. State-of-the-art methods hence solve a layer-wise mask selection problem, the problem of finding a pruning mask which minimizes the per-layer pruning error on a small set of calibration data. Exactly solving this problem to optimality using Integer Programming (IP) solvers is computationally infeasible due to its combinatorial nature and the size of the search space, and existing approaches therefore rely on approximations or heuristics. In this work, we demonstrate that the mask selection problem can be made drastically more tractable at LLM scale. To that end, we decouple the rows by enforcing equal sparsity levels per row. This allows us to derive optimal 1-swaps (exchanging one kept and one pruned weight) that can be computed efficiently using the Gram matrix of the calibration data. Using these observations, we propose a tractable and simple 1-swap algorithm that warm starts from any pruning mask, runs efficiently on GPUs at LLM scale, and is essentially hyperparameter-free. We demonstrate that our approach reduces per-layer pruning error by up to 60% over Wanda (Sun et al., 2023) and consistently improves perplexity and zero-shot accuracy across state-of-the-art GPT architectures.
@article{zimmer2025sparseswaps, title = {SparseSwaps: Tractable LLM Pruning Mask Refinement at Scale}, author = {Zimmer, Max and Roux, Christophe and Wagner, Moritz and Hendrych, Deborah and Pokutta, Sebastian}, journal = {arXiv preprint arXiv:2512.10922}, year = {2025}, } -
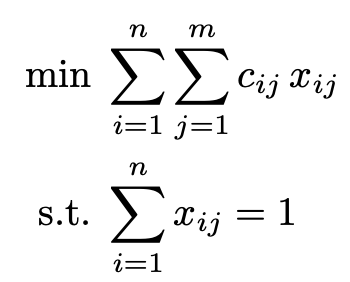 D. Kuzinowicz, P. Lichocki, G. Mexi, M. E. Pfetsch, S. Pokutta, and 1 more authorPreprintarXiv preprint arXiv:2512.10507 2025
D. Kuzinowicz, P. Lichocki, G. Mexi, M. E. Pfetsch, S. Pokutta, and 1 more authorPreprintarXiv preprint arXiv:2512.10507 2025This article investigates the interplay of rounding objective coefficients in binary programs and almost symmetries. Empirically, reducing the number of significant bits through rounding often leads to instances that are easier to solve. One reason can be that the amount of symmetries increases, which enables solvers to be more effective when they are exploited. This can signify that the original instance contains ’almost symmetries’. Furthermore, solving the rounded problems provides approximations to the original objective values. We empirically investigate these relations on instances of the capacitated facility location problem, the knapsack problem and a diverse collection of additional instances, using the solvers SCIP and CP-SAT. For all investigated problem classes, we show empirically that this yields faster algorithms with guaranteed solution quality. The influence of symmetry depends on the instance type and solver.
@article{kuzinowicz2025objective, title = {Objective Coefficient Rounding and Almost Symmetries in Binary Programs}, author = {Kuzinowicz, Dominik and Lichocki, Paweł and Mexi, Gioni and Pfetsch, Marc E. and Pokutta, Sebastian and Zimmer, Max}, journal = {arXiv preprint arXiv:2512.10507}, year = {2025}, } -
 M. Wagner, C. Roux, M. Zimmer, and S. PokuttaPreprintarXiv preprint arXiv:2510.14444 2025
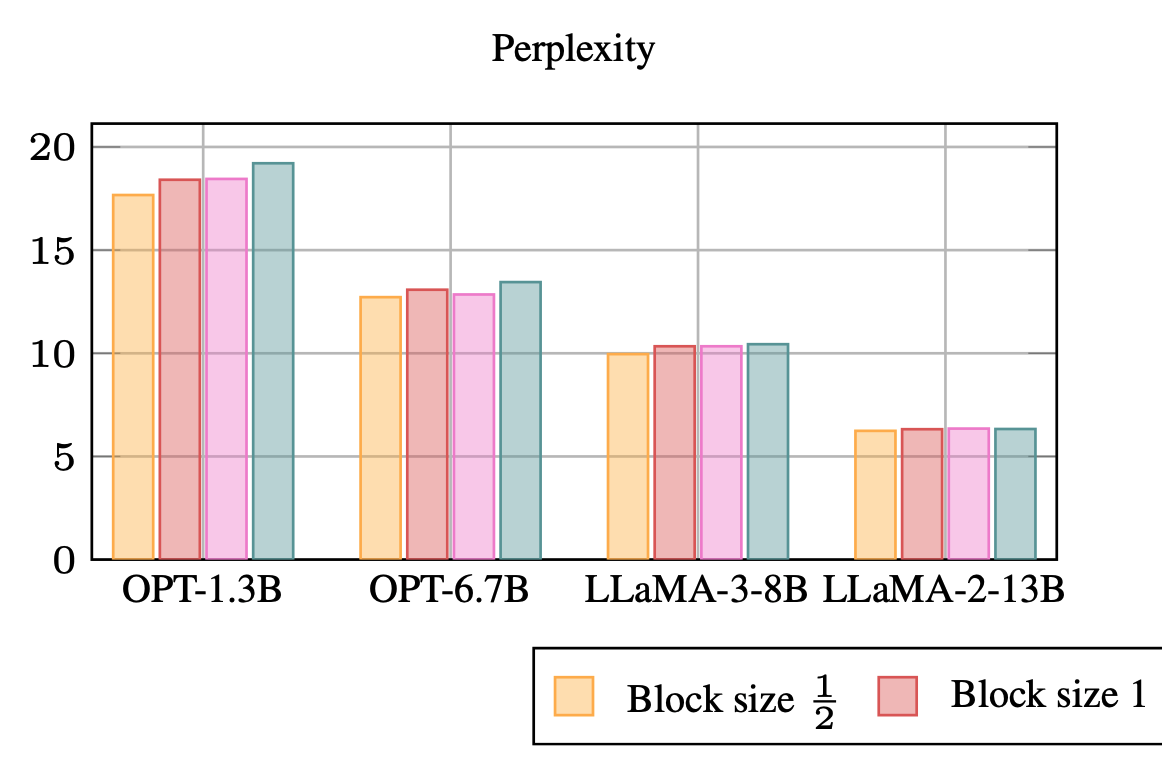
M. Wagner, C. Roux, M. Zimmer, and S. PokuttaPreprintarXiv preprint arXiv:2510.14444 2025While Neural Network pruning typically requires retraining the model to recover pruning-induced performance degradation, state-of-the-art Large Language Models (LLMs) pruning methods instead solve a layer-wise mask selection and reconstruction problem on a small set of calibration data to avoid full retraining, as it is considered computationally infeasible for LLMs. Reconstructing single matrices in isolation has favorable properties, such as convexity of the objective and significantly reduced memory requirements compared to full retraining. In practice, however, reconstruction is often implemented at coarser granularities, e.g., reconstructing a whole transformer block against its dense activations instead of a single matrix. In this work, we study the key design choices when reconstructing or retraining the remaining weights after pruning. We conduct an extensive computational study on state-of-the-art GPT architectures, and report several surprising findings that challenge common intuitions about retraining after pruning. In particular, we observe a free lunch scenario: reconstructing attention and MLP components separately within each transformer block is nearly the most resource-efficient yet achieves the best perplexity. Most importantly, this Pareto-optimal setup achieves better performance than full retraining, despite requiring only a fraction of the memory. Furthermore, we demonstrate that simple and efficient pruning criteria such as Wanda can outperform much more complex approaches when the reconstruction step is properly executed, highlighting its importance. Our findings challenge the narrative that retraining should be avoided at all costs and provide important insights into post-pruning performance recovery for LLMs.
@article{wagner2025freelunchllmcompression, title = {A Free Lunch in LLM Compression: Revisiting Retraining after Pruning}, author = {Wagner, Moritz and Roux, Christophe and Zimmer, Max and Pokutta, Sebastian}, journal = {arXiv preprint arXiv:2510.14444}, year = {2025}, } -
 C. Roux, M. Zimmer, A. d’Aspremont, and S. PokuttaPreprintarXiv preprint arXiv:2510.13713 2025
C. Roux, M. Zimmer, A. d’Aspremont, and S. PokuttaPreprintarXiv preprint arXiv:2510.13713 2025Pruning is a common technique to reduce the compute and storage requirements of Neural Networks. While conventional approaches typically retrain the model to recover pruning-induced performance degradation, state-of-the-art Large Language Model (LLM) pruning methods operate layer-wise, minimizing the per-layer pruning error on a small calibration dataset to avoid full retraining, which is considered computationally prohibitive for LLMs. However, finding the optimal pruning mask is a hard combinatorial problem and solving it to optimality is intractable. Existing methods hence rely on greedy heuristics that ignore the weight interactions in the pruning objective. In this work, we instead consider the convex relaxation of these combinatorial constraints and solve the resulting problem using the Frank-Wolfe (FW) algorithm. Our method drastically reduces the per-layer pruning error, outperforms strong baselines on state-of-the-art GPT architectures, and remains memory-efficient. We provide theoretical justification by showing that, combined with the convergence guarantees of the FW algorithm, we obtain an approximate solution to the original combinatorial problem upon rounding the relaxed solution to integrality.
@article{roux2025dontbegreedyjustrelax, title = {Don't Be Greedy, Just Relax! Pruning LLMs via Frank-Wolfe}, author = {Roux, Christophe and Zimmer, Max and d'Aspremont, Alexandre and Pokutta, Sebastian}, journal = {arXiv preprint arXiv:2510.13713}, year = {2025}, } -
 H. Kera, N. Pelleriti, Y. Ishihara, M. Zimmer, and S. PokuttaNEURIPS25 Advances in Neural Information Processing Systems 2025
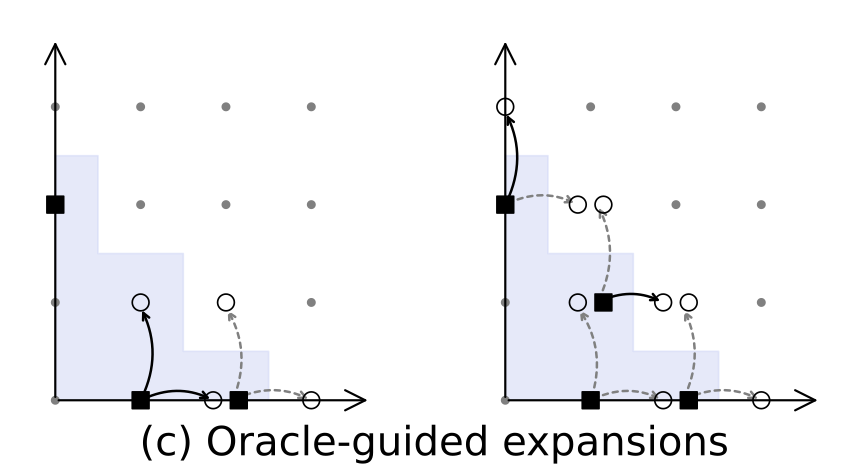
H. Kera, N. Pelleriti, Y. Ishihara, M. Zimmer, and S. PokuttaNEURIPS25 Advances in Neural Information Processing Systems 2025Solving systems of polynomial equations, particularly those with finitely many solutions, is a crucial challenge across many scientific fields. Traditional methods like Gröbner and Border bases are fundamental but suffer from high computational costs, which have motivated recent Deep Learning approaches to improve efficiency, albeit at the expense of output correctness. In this work, we introduce the Oracle Border Basis Algorithm, the first Deep Learning approach that accelerates Border basis computation while maintaining output guarantees. To this end, we design and train a Transformer-based oracle that identifies and eliminates computationally expensive reduction steps, which we find to dominate the algorithm’s runtime. By selectively invoking this oracle during critical phases of computation, we achieve substantial speedup factors of up to 3.5x compared to the base algorithm, without compromising the correctness of results. To generate the training data, we develop a sampling method and provide the first sampling theorem for border bases. We construct a tokenization and embedding scheme tailored to monomial-centered algebraic computations, resulting in a compact and expressive input representation, which reduces the number of tokens to encode an n-variate polynomial by a factor of O(n). Our learning approach is data efficient, stable, and a practical enhancement to traditional computer algebra algorithms and symbolic computation.
@inproceedings{kera2025computationalalgebraattentiontransformer, title = {Computational Algebra with Attention: Transformer Oracles for Border Basis Algorithms}, author = {Kera, Hiroshi and Pelleriti, Nico and Ishihara, Yuki and Zimmer, Max and Pokutta, Sebastian}, booktitle = {Advances in Neural Information Processing Systems}, volume = {38}, year = {2025}, } -
 ICML25 Forty-second International Conference on Machine Learning (Oral presentation, top 1%) 2025
ICML25 Forty-second International Conference on Machine Learning (Oral presentation, top 1%) 2025We demonstrate how neural networks can drive mathematical discovery through a case study of the Hadwiger-Nelson problem, a long-standing open problem from discrete geometry and combinatorics about coloring the plane avoiding monochromatic unit-distance pairs. Using neural networks as approximators, we reformulate this mixed discrete-continuous geometric coloring problem as an optimization task with a probabilistic, differentiable loss function. This enables gradient-based exploration of admissible configurations that most significantly led to the discovery of two novel six-colorings, providing the first improvements in thirty years to the off-diagonal variant of the original problem (Mundinger et al., 2024a). Here, we establish the underlying machine learning approach used to obtain these results and demonstrate its broader applicability through additional results and numerical insights.
@inproceedings{mundinger2025neural, title = {Neural Discovery in Mathematics: Do Machines Dream of Colored Planes?}, author = {Mundinger, Konrad and Zimmer, Max and Kiem, Aldo and Spiegel, Christoph and Pokutta, Sebastian}, booktitle = {Forty-second International Conference on Machine Learning}, year = {2025}, url = {https://openreview.net/forum?id=7Tp9zjP9At}, } -
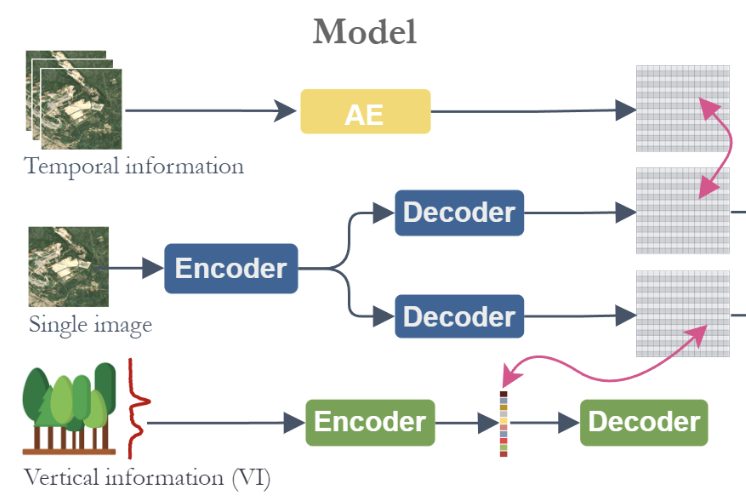 ICML25 Forty-second International Conference on Machine Learning 2025
ICML25 Forty-second International Conference on Machine Learning 2025Significant efforts have been directed towards adapting self-supervised multimodal learning for Earth observation applications. However, existing methods produce coarse patch-sized embeddings, limiting their effectiveness and integration with other modalities like LiDAR. To close this gap, we present DUNIA, an approach to learn pixel-sized embeddings through cross-modal alignment between images and full-waveform LiDAR data. As the model is trained in a contrastive manner, the embeddings can be directly leveraged in the context of a variety of environmental monitoring tasks in a zero-shot setting. In our experiments, we demonstrate the effectiveness of the embeddings for seven such tasks (canopy height mapping, fractional canopy cover, land cover mapping, tree species identification, plant area index, crop type classification, and per-pixel waveform-based vertical structure mapping). The results show that the embeddings, along with zero-shot classifiers, often outperform specialized supervised models, even in low data regimes. In the fine-tuning setting, we show strong low-shot capabilities with performances near or better than state-of-the-art on five out of six tasks.
@inproceedings{fayad2025dunia, title = {DUNIA: Pixel-Sized Embeddings via Cross-Modal Alignment for Earth Observation Applications}, author = {Fayad, Ibrahim and Zimmer, Max and Schwartz, Martin and Ciais, Philippe and Gieseke, Fabian and Belouze, Gabriel and Brood, Sarah and De Truchis, Aurelien and d'Aspremont, Alexandre}, booktitle = {Forty-second International Conference on Machine Learning}, year = {2025}, url = {https://openreview.net/forum?id=JXCiQteuOv}, } -
 N. Pelleriti, M. Zimmer, E. Wirth, and S. PokuttaICML25 Forty-second International Conference on Machine Learning 2025
N. Pelleriti, M. Zimmer, E. Wirth, and S. PokuttaICML25 Forty-second International Conference on Machine Learning 2025Deep neural networks have reshaped modern machine learning by learning powerful latent representations that often align with the manifold hypothesis: high-dimensional data lie on lower-dimensional manifolds. In this paper, we establish a connection between manifold learning and computational algebra by demonstrating how vanishing ideals can characterize the latent manifolds of deep networks. To that end, we propose a new neural architecture that (i) truncates a pretrained network at an intermediate layer, (ii) approximates each class manifold via polynomial generators of the vanishing ideal, and (iii) transforms the resulting latent space into linearly separable features through a single polynomial layer. The resulting models have significantly fewer layers than their pretrained baselines, while maintaining comparable accuracy, achieving higher throughput, and utilizing fewer parameters. Furthermore, drawing on spectral complexity analysis, we derive sharper theoretical guarantees for generalization, showing that our approach can in principle offer tighter bounds than standard deep networks. Numerical experiments confirm the effectiveness and efficiency of the proposed approach.
@inproceedings{pelleriti2025approximatinglatentmanifoldsneural, title = {Approximating Latent Manifolds in Neural Networks via Vanishing Ideals}, author = {Pelleriti, Nico and Zimmer, Max and Wirth, Elias and Pokutta, Sebastian}, booktitle = {Forty-second International Conference on Machine Learning}, year = {2025}, url = {https://openreview.net/forum?id=WYlerYGDPL}, } -
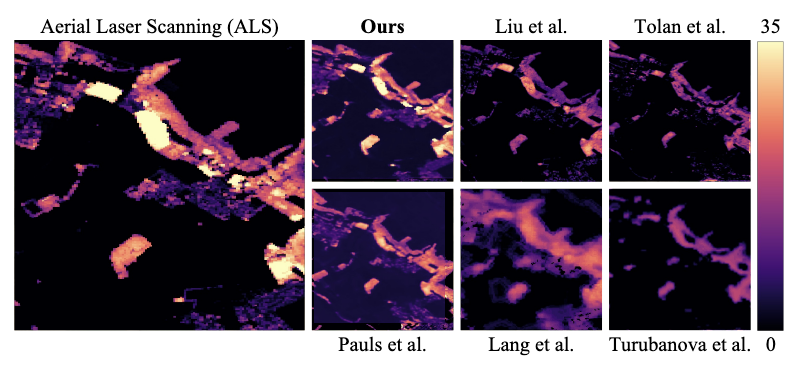 ICML25 Forty-second International Conference on Machine Learning 2025
ICML25 Forty-second International Conference on Machine Learning 2025With the rise in global greenhouse gas emissions, accurate large-scale tree canopy height maps are essential for understanding forest structure, estimating above-ground biomass, and monitoring ecological disruptions. To this end, we present a novel approach to generate large-scale, high-resolution canopy height maps over time. Our model accurately predicts canopy height over multiple years given Sentinel-2 time series satellite data. Using GEDI LiDAR data as the ground truth for training the model, we present the first 10m resolution temporal canopy height map of the European continent for the period 2019-2022. As part of this product, we also offer a detailed canopy height map for 2020, providing more precise estimates than previous studies. Our pipeline and the resulting temporal height map are publicly available, enabling comprehensive large-scale monitoring of forests and, hence, facilitating future research and ecological analyses. For an interactive viewer, see this https URL.
@inproceedings{pauls2025capturing, title = {Capturing Temporal Dynamics in Large-Scale Canopy Tree Height Estimation}, author = {Pauls, Jan and Zimmer, Max and Turan, Berkant and Saatchi, Sassan and Ciais, Philippe and Pokutta, Sebastian and Gieseke, Fabian}, booktitle = {Forty-second International Conference on Machine Learning}, year = {2025}, url = {https://openreview.net/forum?id=ri1cs3vtXX}, } -
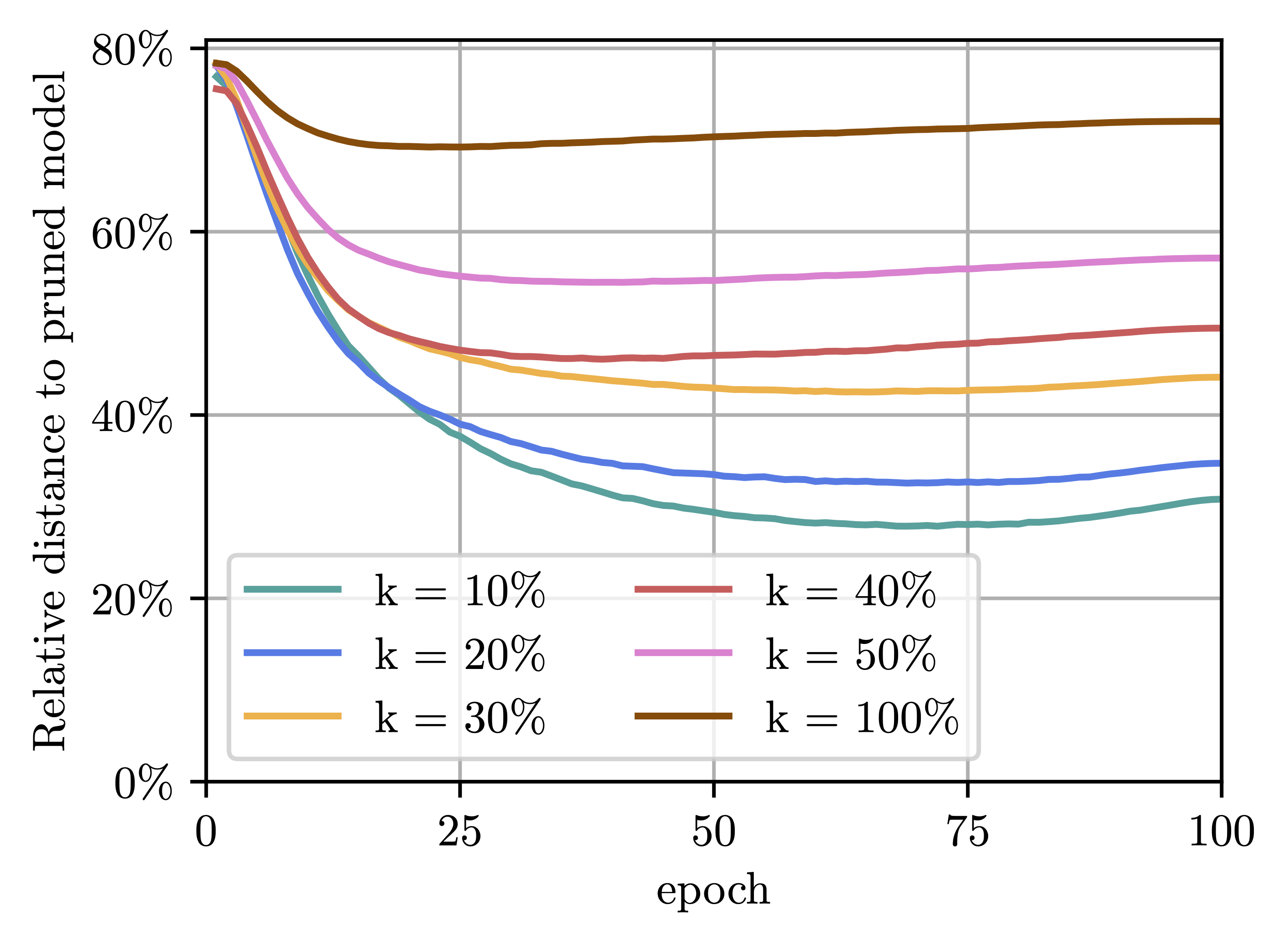 M. Zimmer, C. Spiegel, and S. PokuttaJournal Mathematical Optimization for Machine Learning 2025
M. Zimmer, C. Spiegel, and S. PokuttaJournal Mathematical Optimization for Machine Learning 2025Many existing Neural Network pruning approaches either rely on retraining to compensate for pruning-caused performance degradation or they induce strong biases to converge to a specific sparse solution throughout training. A third paradigm obtains a wide range of compression ratios from a single dense training run while also avoiding retraining. Recent work of Pokutta et al. (2020) and Miao et al. (2022) suggests that the Stochastic Frank-Wolfe (SFW) algorithm is particularly suited for training state-of-the-art models that are robust to compression. We propose leveraging k-support norm ball constraints and demonstrate significant improvements over the results of Miao et al. (2022) in the case of unstructured pruning. We also extend these ideas to the structured pruning domain and propose novel approaches to both ensure robustness to the pruning of convolutional filters as well as to low-rank tensor decompositions of convolutional layers. In the latter case, our approach performs on-par with nuclear-norm regularization baselines while requiring only half of the computational resources. Our findings also indicate that the robustness of SFW-trained models largely depends on the gradient rescaling of the learning rate and we establish a theoretical foundation for that practice.
@inbook{ZimmerSpiegelPokutta+2025+137+168, url = {https://doi.org/10.1515/9783111376776-010}, title = {Compression-aware Training of Neural Networks using Frank-Wolfe}, booktitle = {Mathematical Optimization for Machine Learning}, author = {Zimmer, Max and Spiegel, Christoph and Pokutta, Sebastian}, editor = {Fackeldey, Konstantin and Kannan, Aswin and Pokutta, Sebastian and Sharma, Kartikey and Walter, Daniel and Walther, Andrea and Weiser, Martin}, publisher = {De Gruyter}, address = {Berlin, Boston}, pages = {137--168}, doi = {doi:10.1515/9783111376776-010}, isbn = {9783111376776}, year = {2025}, } -
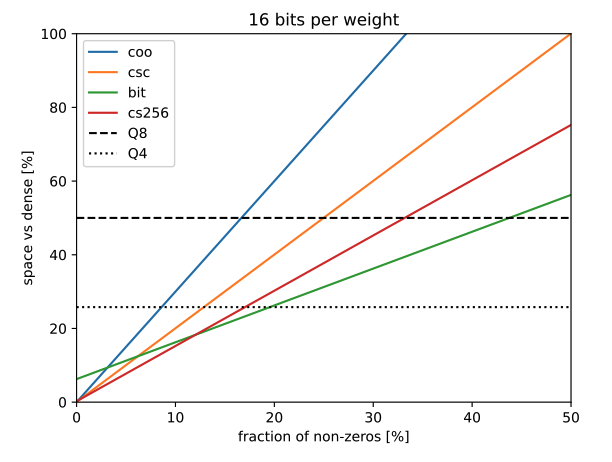 M. Lasby, M. Zimmer, S. Pokutta, and E. SchultheisWorkshop ICLR25 Workshop on Sparsity in LLMs (SLLM) 2025
M. Lasby, M. Zimmer, S. Pokutta, and E. SchultheisWorkshop ICLR25 Workshop on Sparsity in LLMs (SLLM) 2025Storing the weights of large language models (LLMs) in GPU memory for local inference is challenging due to their size. While quantization has proven successful in reducing the memory footprint of LLMs, unstructured pruning introduces overhead by requiring the non-pruned weights’ location to be encoded. This overhead hinders the efficient combination of quantization and unstructured pruning, especially for smaller batch sizes common in inference scenarios. To address this, we propose the CS256 storage format, which offers a better balance between space efficiency and hardware acceleration compared to existing formats. CS256 partitions the weight matrix into tiles and uses a hierarchical indexing scheme to locate non-zero values, reducing the overhead associated with storing sparsity patterns. Our preliminary results with one-shot pruning of LLMs show that CS256 matches the performance of unstructured sparsity while being more hardware-friendly.
@inproceedings{lasby2025compressed, title = {Compressed Sparse Tiles for Memory-Efficient Unstructured and Semi-Structured Sparsity}, author = {Lasby, Mike and Zimmer, Max and Pokutta, Sebastian and Schultheis, Erik}, booktitle = {Sparsity in LLMs (SLLM): Deep Dive into Mixture of Experts, Quantization, Hardware, and Inference}, year = {2025}, url = {https://openreview.net/forum?id=iso0KV2HVq}, } -
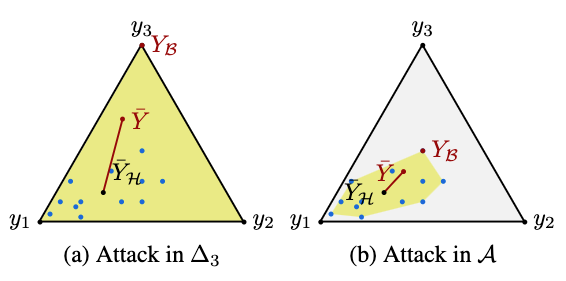 C. Roux, M. Zimmer, and S. PokuttaICLR25 The Thirteenth International Conference on Learning Representations 2025
C. Roux, M. Zimmer, and S. PokuttaICLR25 The Thirteenth International Conference on Learning Representations 2025Federated Learning (FL) algorithms using Knowledge Distillation (KD) have received increasing attention due to their favorable properties with respect to privacy, non-i.i.d. data and communication cost. These methods depart from transmitting model parameters and, instead, communicate information about a learning task by sharing predictions on a public dataset. In this work, we study the performance of such approaches in the byzantine setting, where a subset of the clients act in an adversarial manner aiming to disrupt the learning process. We show that KD-based FL algorithms are remarkably resilient and analyze how byzantine clients can influence the learning process compared to Federated Averaging. Based on these insights, we introduce two new byzantine attacks and demonstrate that they are effective against prior byzantine-resilient methods. Additionally, we propose FilterExp, a novel method designed to enhance the byzantine resilience of KD-based FL algorithms and demonstrate its efficacy. Finally, we provide a general method to make attacks harder to detect, improving their effectiveness.
@inproceedings{roux2024byzantine, author = {Roux, Christophe and Zimmer, Max and Pokutta, Sebastian}, title = {On the Byzantine-Resilience of Distillation-Based Federated Learning}, year = {2025}, booktitle = {The Thirteenth International Conference on Learning Representations}, url = {https://openreview.net/forum?id=of6EuHT7de}, } -
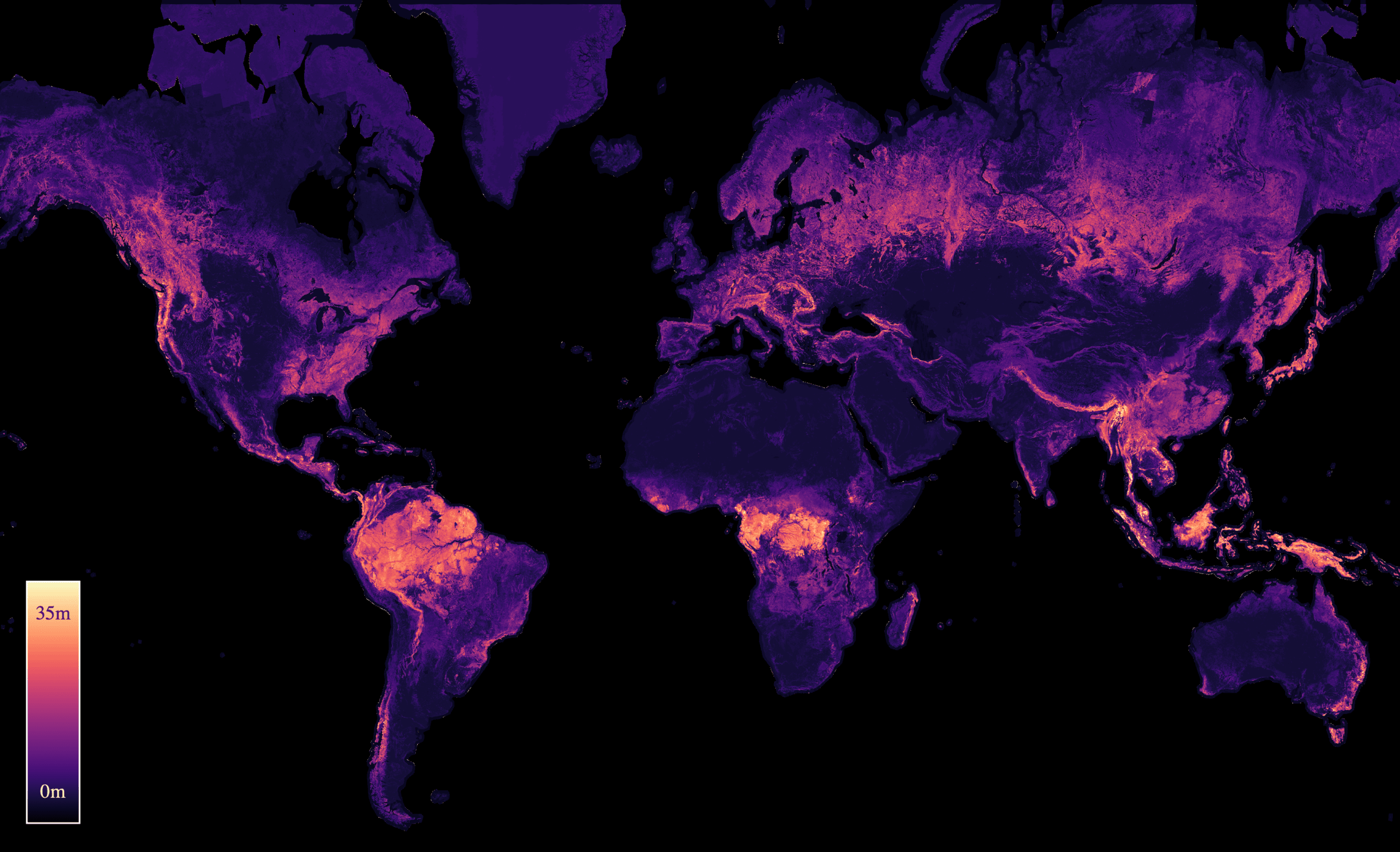 ICML24 Forty-first International Conference on Machine Learning 2024
ICML24 Forty-first International Conference on Machine Learning 2024We propose a framework for global-scale canopy height estimation based on satellite data. Our model leverages advanced data preprocessing techniques, resorts to a novel loss function designed to counter geolocation inaccuracies inherent in the ground-truth height measurements, and employs data from the Shuttle Radar Topography Mission to effectively filter out erroneous labels in mountainous regions, enhancing the reliability of our predictions in those areas. A comparison between predictions and ground-truth labels yields an MAE / RMSE of 2.43 / 4.73 (meters) overall and 4.45 / 6.72 (meters) for trees taller than five meters, which depicts a substantial improvement compared to existing global-scale maps. The resulting height map as well as the underlying framework will facilitate and enhance ecological analyses at a global scale, including, but not limited to, large-scale forest and biomass monitoring.
@inproceedings{pauls2024estimating, title = {Estimating Canopy Height at Scale}, author = {Pauls, Jan and Zimmer, Max and Kelly, Una M. and Schwartz, Martin and Saatchi, Sassan and Ciais, Philippe and Pokutta, Sebastian and Brandt, Martin and Gieseke, Fabian}, booktitle = {Forty-first International Conference on Machine Learning}, year = {2024}, url = {https://openreview.net/forum?id=ZzCY0fRver}, } -
 JournalGeombinatorics Quarterly 2024
JournalGeombinatorics Quarterly 2024We present two novel six-colorings of the Euclidean plane that avoid monochromatic pairs of points at unit distance in five colors and monochromatic pairs at another specified distance d in the sixth color. Such colorings have previously been known to exist for 0.41 < \sqrt2 - 1 \le d \le 1 / \sqrt5 < 0.45. Our results significantly expand that range to 0.354 \le d \le 0.657, the first improvement in 30 years. Notably, the constructions underlying this were derived by formalizing colorings suggested by a custom machine learning approach.
@article{mundinger2024extending, author = {Mundinger, Konrad and Pokutta, Sebastian and Spiegel, Christoph and Zimmer, Max}, journal = {Geombinatorics Quarterly}, title = {Extending the Continuum of Six-Colorings}, year = {2024}, volume = {XXXIV}, archiveprefix = {arXiv}, eprint = {2404.05509}, url = {https://geombina.uccs.edu/past-issues/volume-xxxiv}, } -
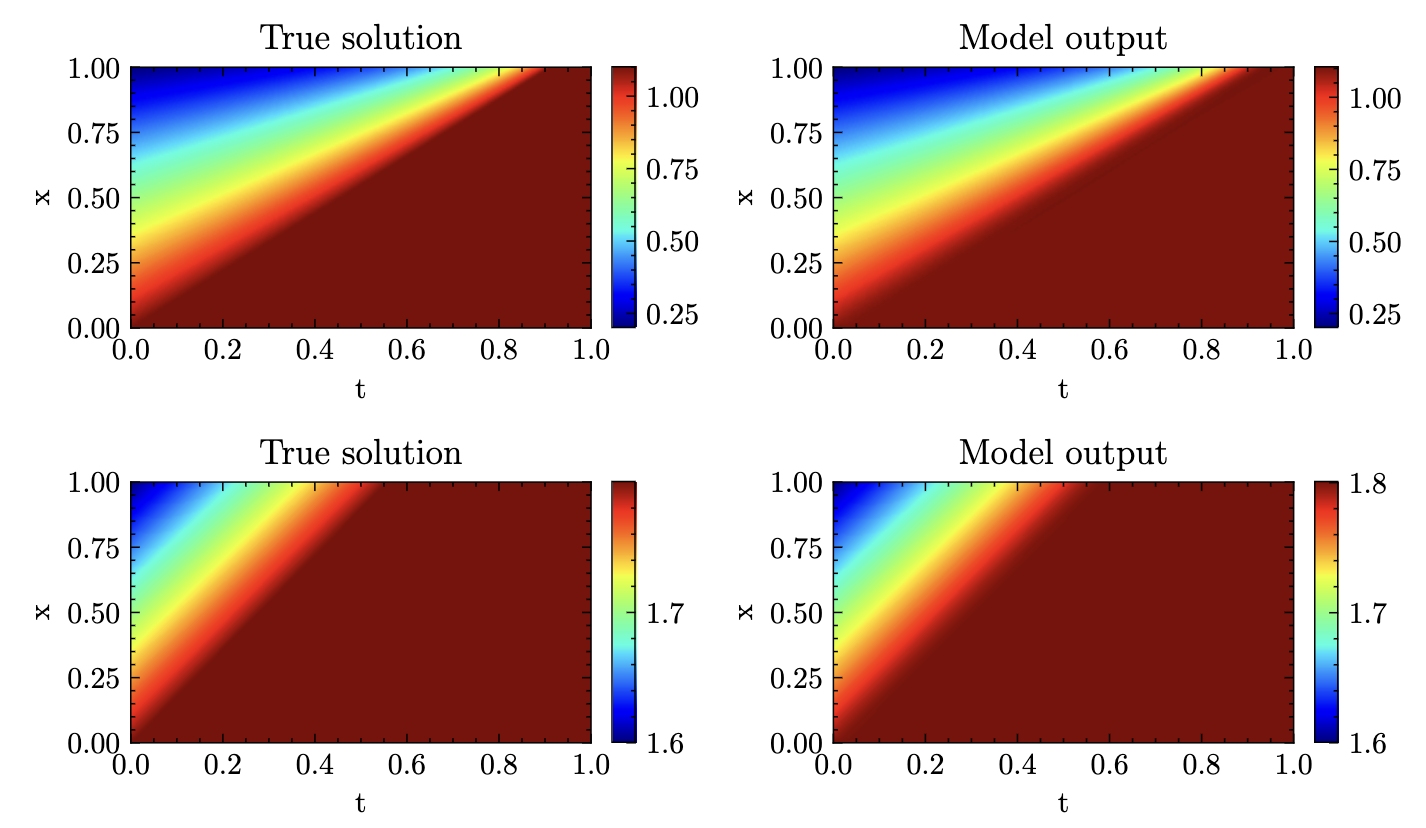 K. Mundinger, M. Zimmer, and S. PokuttaWorkshop ICLR24 Workshop on AI4DifferentialEquations In Science 2024
K. Mundinger, M. Zimmer, and S. PokuttaWorkshop ICLR24 Workshop on AI4DifferentialEquations In Science 2024We introduce Neural Parameter Regression (NPR), a novel framework specifically developed for learning solution operators in Partial Differential Equations (PDEs). Tailored for operator learning, this approach surpasses traditional DeepONets (Lu et al., 2021) by employing Physics-Informed Neural Network (PINN, Raissi et al., 2019) techniques to regress Neural Network (NN) parameters. By parametrizing each solution based on specific initial conditions, it effectively approximates a mapping between function spaces. Our method enhances parameter efficiency by incorporating low-rank matrices, thereby boosting computational efficiency and scalability. The framework shows remarkable adaptability to new initial and boundary conditions, allowing for rapid fine-tuning and inference, even in cases of out-of-distribution examples.
@inproceedings{mundinger2024neural, author = {Mundinger, Konrad and Zimmer, Max and Pokutta, Sebastian}, title = {Neural Parameter Regression for Explicit Representations of PDE Solution Operators}, year = {2024}, booktitle = {ICLR 2024 Workshop on AI4DifferentialEquations In Science}, url = {https://openreview.net/forum?id=6Z0q0dzSJQ}, } -
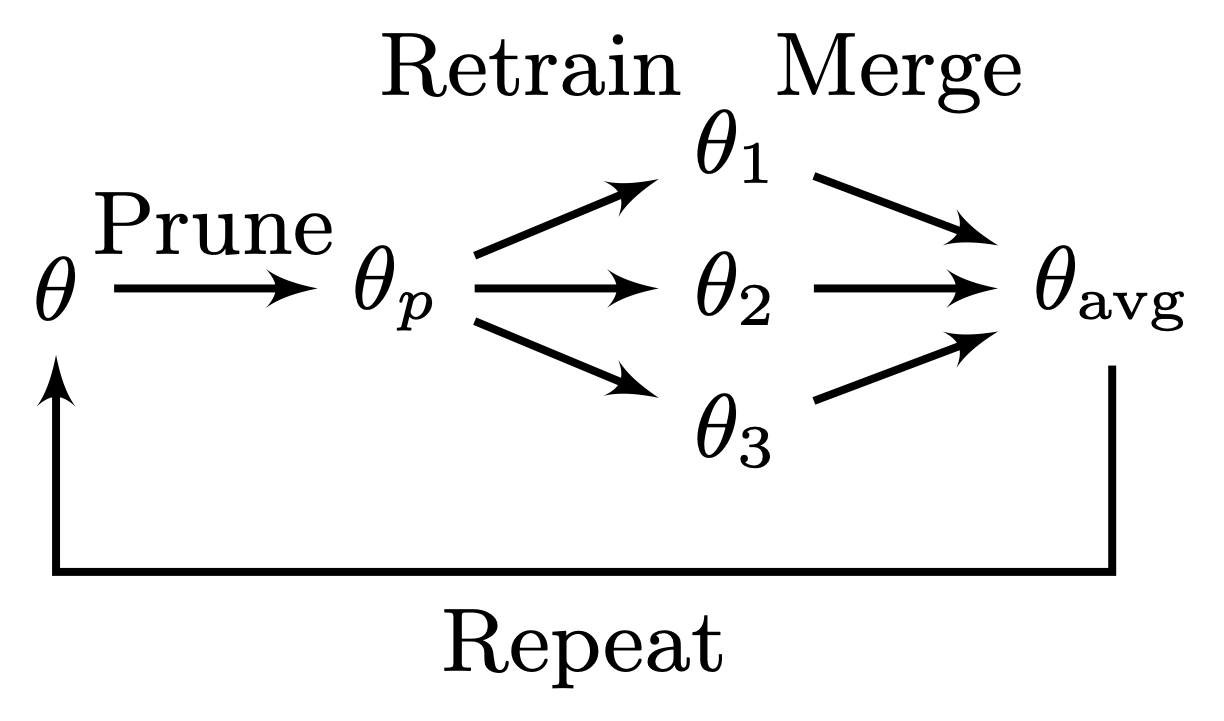 M. Zimmer, C. Spiegel, and S. PokuttaICLR24 The Twelfth International Conference on Learning Representations 2024
M. Zimmer, C. Spiegel, and S. PokuttaICLR24 The Twelfth International Conference on Learning Representations 2024Neural networks can be significantly compressed by pruning, leading to sparse models requiring considerably less storage and floating-point operations while maintaining predictive performance. Model soups (Wortsman et al., 2022) improve generalization and out-of-distribution performance by averaging the parameters of multiple models into a single one without increased inference time. However, identifying models in the same loss basin to leverage both sparsity and parameter averaging is challenging, as averaging arbitrary sparse models reduces the overall sparsity due to differing sparse connectivities. In this work, we address these challenges by demonstrating that exploring a single retraining phase of Iterative Magnitude Pruning (IMP) with varying hyperparameter configurations, such as batch ordering or weight decay, produces models that are suitable for averaging and share the same sparse connectivity by design. Averaging these models significantly enhances generalization performance compared to their individual components. Building on this idea, we introduce Sparse Model Soups (SMS), a novel method for merging sparse models by initiating each prune-retrain cycle with the averaged model of the previous phase. SMS maintains sparsity, exploits sparse network benefits being modular and fully parallelizable, and substantially improves IMP’s performance. Additionally, we demonstrate that SMS can be adapted to enhance the performance of state-of-the-art pruning during training approaches.
@inproceedings{zimmer2023sparse, title = {Sparse Model Soups: A Recipe for Improved Pruning via Model Averaging}, author = {Zimmer, Max and Spiegel, Christoph and Pokutta, Sebastian}, booktitle = {The Twelfth International Conference on Learning Representations}, year = {2024}, } -
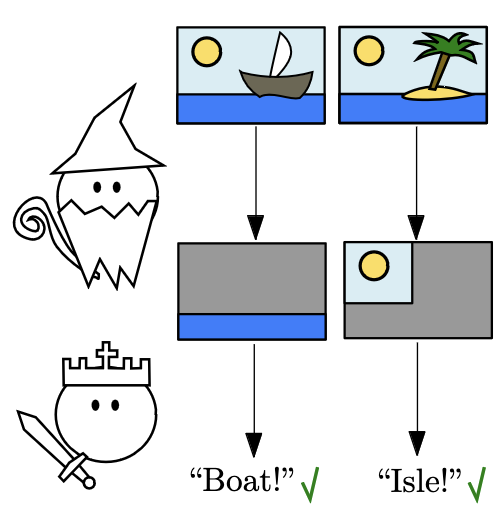
We propose an interactive multi-agent classifier that provides provable interpretability guarantees even for complex agents such as neural networks. These guarantees consist of lower bounds on the mutual information between selected features and the classification decision. Our results are inspired by the Merlin-Arthur protocol from Interactive Proof Systems and express these bounds in terms of measurable metrics such as soundness and completeness. Compared to existing interactive setups, we rely neither on optimal agents nor on the assumption that features are distributed independently. Instead, we use the relative strength of the agents as well as the new concept of Asymmetric Feature Correlation which captures the precise kind of correlations that make interpretability guarantees difficult. We evaluate our results on two small-scale datasets where high mutual information can be verified explicitly.
@inproceedings{waldchen2024interpretability, title = {Interpretability Guarantees with Merlin-Arthur Classifiers}, author = {W{\"a}ldchen, Stephan and Sharma, Kartikey and Turan, Berkant and Zimmer, Max and Pokutta, Sebastian}, booktitle = {International Conference on Artificial Intelligence and Statistics}, year = {2024}, } -
 M. Zimmer, M. Andoni, C. Spiegel, and S. PokuttaPreprintarXiv preprint arXiv:2312.15230 2023
M. Zimmer, M. Andoni, C. Spiegel, and S. PokuttaPreprintarXiv preprint arXiv:2312.15230 2023Neural Networks can be effectively compressed through pruning, significantly reducing storage and compute demands while maintaining predictive performance. Simple yet effective methods like magnitude pruning remove less important parameters and typically require a costly retraining procedure to restore performance. However, with the rise of LLMs, full retraining has become infeasible due to memory and compute constraints. This study challenges the practice of retraining all parameters by showing that updating a small subset of highly expressive parameters can suffice to recover or even enhance performance after pruning. Surprisingly, retraining just 0.01%-0.05% of the parameters in GPT-architectures can match the performance of full retraining across various sparsity levels, significantly reducing compute and memory requirements, and enabling retraining of models with up to 30 billion parameters on a single GPU in minutes. To bridge the gap to full retraining in the high sparsity regime, we introduce two novel LoRA variants that, unlike standard LoRA, allow merging adapters back without compromising sparsity. Going a step further, we show that these methods can be applied for memory-efficient layer-wise reconstruction, significantly enhancing state-of-the-art retraining-free methods like Wanda (Sun et al., 2023) and SparseGPT (Frantar & Alistarh, 2023). Our findings present a promising alternative to avoiding retraining.
@article{zimmer2023perp, author = {Zimmer, Max and Andoni, Megi and Spiegel, Christoph and Pokutta, Sebastian}, title = {PERP: Rethinking the Prune-Retrain Paradigm in the Era of LLMs}, year = {2023}, journal = {arXiv preprint arXiv:2312.15230}, } -
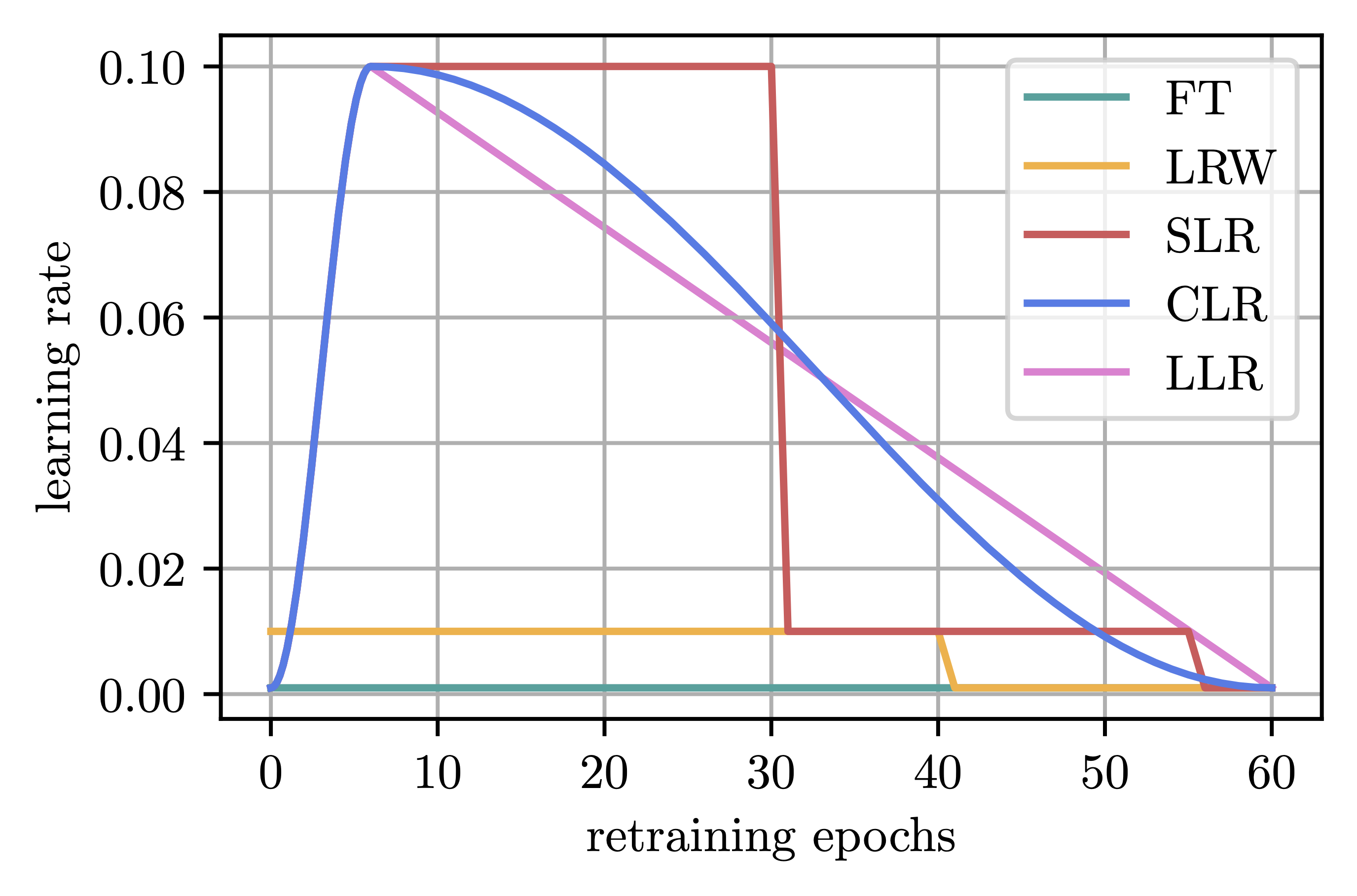 M. Zimmer, C. Spiegel, and S. PokuttaICLR23 The Eleventh International Conference on Learning Representations 2023
M. Zimmer, C. Spiegel, and S. PokuttaICLR23 The Eleventh International Conference on Learning Representations 2023Many Neural Network Pruning approaches consist of several iterative training and pruning steps, seemingly losing a significant amount of their performance after pruning and then recovering it in the subsequent retraining phase. Recent works of Renda et al. (2020) and Le & Hua (2021) demonstrate the significance of the learning rate schedule during the retraining phase and propose specific heuristics for choosing such a schedule for IMP (Han et al., 2015). We place these findings in the context of the results of Li et al. (2020) regarding the training of models within a fixed training budget and demonstrate that, consequently, the retraining phase can be massively shortened using a simple linear learning rate schedule. Improving on existing retraining approaches, we additionally propose a method to adaptively select the initial value of the linear schedule. Going a step further, we propose similarly imposing a budget on the initial dense training phase and show that the resulting simple and efficient method is capable of outperforming significantly more complex or heavily parameterized state-of-the-art approaches that attempt to sparsify the network during training. These findings not only advance our understanding of the retraining phase, but more broadly question the belief that one should aim to avoid the need for retraining and reduce the negative effects of ‘hard’ pruning by incorporating the sparsification process into the standard training.
@inproceedings{Zimmer2023, author = {Zimmer, Max and Spiegel, Christoph and Pokutta, Sebastian}, booktitle = {The Eleventh International Conference on Learning Representations}, title = {{H}ow {I} {L}earned {T}o {S}top {W}orrying {A}nd {L}ove {R}etraining}, year = {2023}, url = {https://openreview.net/forum?id=_nF5imFKQI}, } -
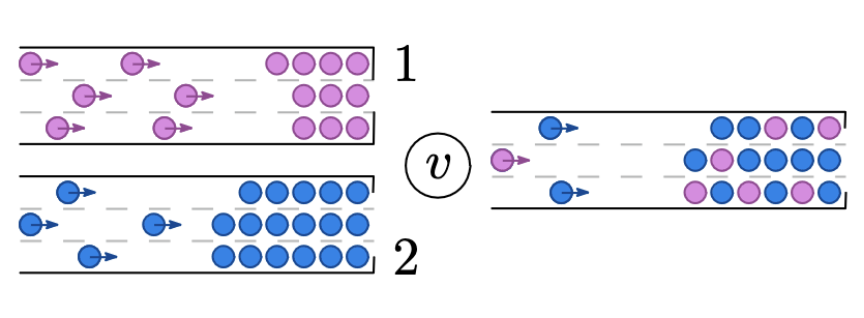 T. Ziemke, L. Sering, L. V. Koch, M. Zimmer, K. Nagel, and 1 more authorJournalTransportation Research Procedia 2021
T. Ziemke, L. Sering, L. V. Koch, M. Zimmer, K. Nagel, and 1 more authorJournalTransportation Research Procedia 2021This study examines the connection between an agent-based transport simulation and Nash flows over time. While the former is able to represent many details of traffic and model large-scale, real-world traffic situations with a co-evolutionary approach, the latter provides an environment for provable mathematical statements and results on exact user equilibria. The flow dynamics of both models are very similar with the main difference that the simulation is discrete in terms of vehicles and time while the flows over time model considers continuous flows and continuous time. This raises the question whether Nash flows over time are the limit of the convergence process when decreasing the vehicle and time step size in the simulation coherently. The experiments presented in this study indicate this strong connection which provides a justification for the analytical model and a theoretical foundation for the simulation.
@article{ziemke2021flows, title = {Flows over time as continuous limits of packet-based network simulations}, author = {Ziemke, Theresa and Sering, Leon and Koch, Laura Vargas and Zimmer, Max and Nagel, Kai and Skutella, Martin}, journal = {Transportation Research Procedia}, volume = {52}, pages = {123--130}, year = {2021}, publisher = {Elsevier}, } -
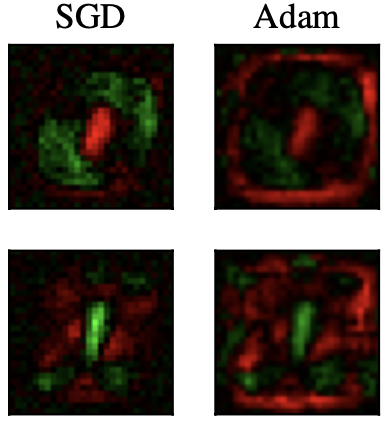 S. Pokutta, C. Spiegel, and M. ZimmerPreprintarXiv preprint arXiv:2010.07243 2020
S. Pokutta, C. Spiegel, and M. ZimmerPreprintarXiv preprint arXiv:2010.07243 2020This paper studies the empirical efficacy and benefits of using projection-free first-order methods in the form of Conditional Gradients, a.k.a. Frank-Wolfe methods, for training Neural Networks with constrained parameters. We draw comparisons both to current state-of-the-art stochastic Gradient Descent methods as well as across different variants of stochastic Conditional Gradients. In particular, we show the general feasibility of training Neural Networks whose parameters are constrained by a convex feasible region using Frank-Wolfe algorithms and compare different stochastic variants. We then show that, by choosing an appropriate region, one can achieve performance exceeding that of unconstrained stochastic Gradient Descent and matching state-of-the-art results relying on L^2-regularization. Lastly, we also demonstrate that, besides impacting performance, the particular choice of constraints can have a drastic impact on the learned representations.
@article{pokutta2020deep, title = {Deep Neural Network training with Frank-Wolfe}, author = {Pokutta, Sebastian and Spiegel, Christoph and Zimmer, Max}, journal = {arXiv preprint arXiv:2010.07243}, year = {2020}, }